
پادشاهِ کُدنویسا شو!

بازنویسی یا Refactoring ساختار داخلی کد بدون تغییر در رفتار بیرونی آن، هنر پنهان مهندسی نرمافزار است. با ظهور مدلهای زبانی بزرگ (LLMs) و دستیارهای هوش مصنوعی (مانند GitHub Copilot، Claude، ChatGPT و ابزارهای تخصصیتر)، این فرآیند فرساینده و پرخطر، وارد فاز جدیدی شده است. هوش مصنوعی دیگر یک ابزار ساده برای تکمیل خودکار کد (Auto-complete) نیست؛ بلکه به عنوان یک همکار استراتژیک در معماری و مدرنسازی نرمافزار نقشآفرینی میکند.
در این مقاله تخصصی، به کالبدشکافی دقیق فرآیند بازنویسی کدهای قدیمی با کمک هوش مصنوعی، الگوهای عملی، تکنیکهای پرامپتنویسی پیشرفته و مدیریت ریسکهای ناشی از آن میپردازیم.
پیش از آنکه ابزار هوش مصنوعی را باز کنیم، باید بدانیم با چه غولی روبرو هستیم. کدهای قدیمی معمولاً با علائم زیر شناخته میشوند:
کدهای اسپاگتی و کوپلینگ بالا (High Coupling): تغییر در یک کلاس یا ماژول، بخش کاملاً بیربطی از سیستم را در سمت دیگر پروژه از کار میاندازد.
پدیده بوهای کد (Code Smells): متدهای چندصد خطی، کلاسهای خداگونه (God Classes) که همه کار انجام میدهند، و استفاده مفرط از ساختارهای شرطی پیچیده.
نبود تستهای خودکار (Lack of Test Coverage): بزرگترین هراس توسعهدهندگان؛ «اگر این خط را تغییر دهم، چه چیزی خراب خواهد شد؟»
فناوریها و الگوهای منسوخ: کدهایی که سالها پیش بر اساس الگوهای آن زمان نوشته شدهاند و اکنون با استانداردهای معماری مدرن (مانند Clean Architecture، DDD یا CQRS) فرسنگها فاصله دارند.
هوش مصنوعی با پردازش سریع الگوها و درک معنایی (Semantic Understanding) کد، میتواند در چهار فاز اصلی بازنویسی به ما کمک کند:
[کد قدیمی] ──> (۱. تحلیل و درک هوش مصنوعی) ──> (۲. تولید تست واحد) ──> (۳. اعمال الگوهای مدرن) ──> [کد بازنویسیشده]
الف) فاز تحلیل و کشف معنایی (Code Understanding)
ب) ایجاد چتر نجات (Automated Test Generation)
ج) تبدیل و مدرنسازی ساختار (Structural Transformation)
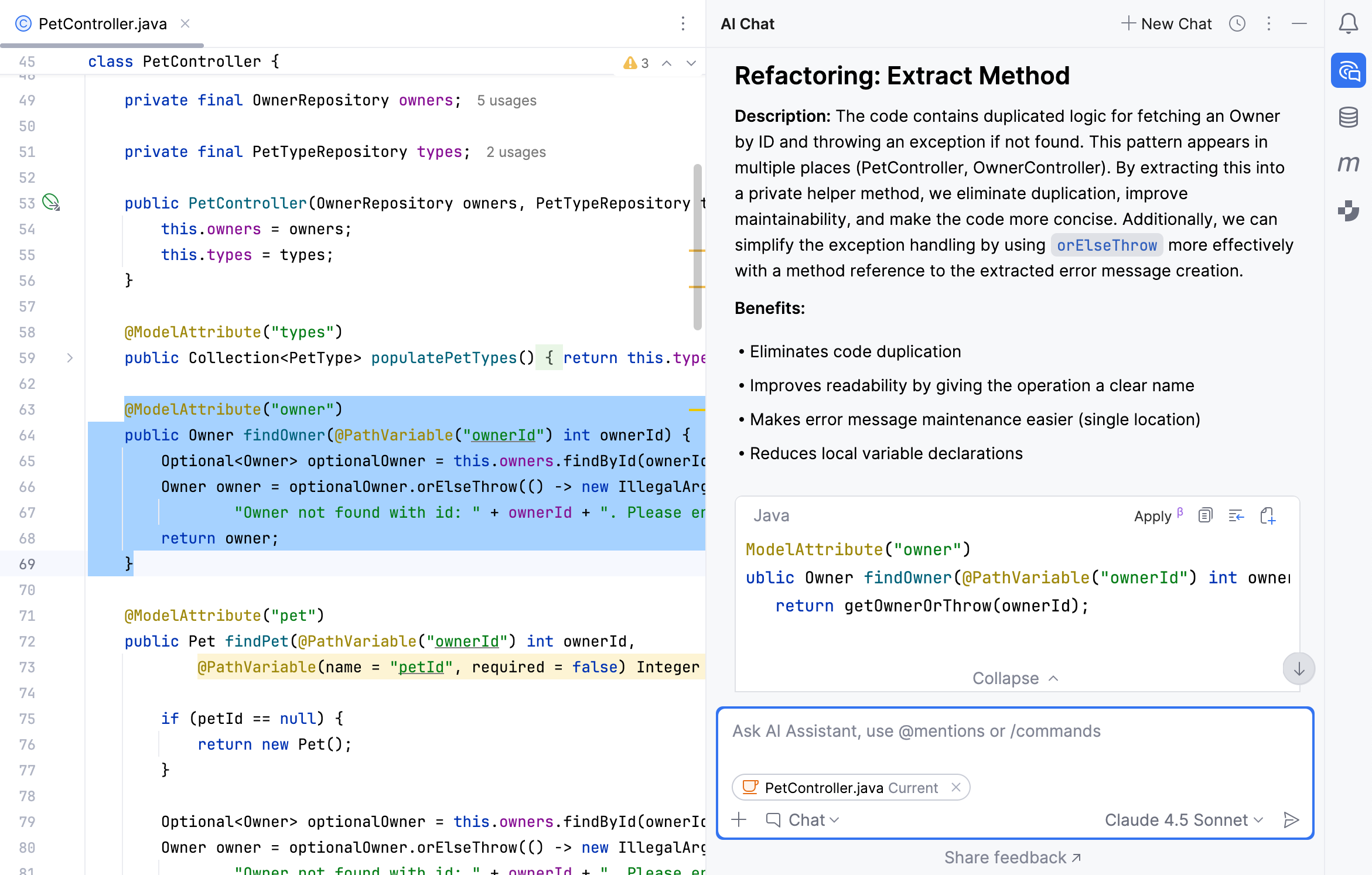
برای کارهای بزرگ، نباید کل فایل را به درون شکم هوش مصنوعی بیندازید و بنویسید "این را بازنویسی کن!". این کار قطعاً به شکست، تولید باگهای مخفی و ایجاد توهمهای محاسباتی (Hallucinations) منجر میشود. فرآیند باید کاملاً مهندسیشده و گامبهگام باشد:
گام اول: ایزولهسازی و تحلیل
ابتدا قطعه کد هدف (یک متد، یک کلاس یا یک سرویس خاص) را جدا کنید. از هوش مصنوعی بخواهید وظیفه اصلی این قطعه کد و وابستگیهای آن را تحلیل کند.
پرامپت پیشنهادی:
"متد زیر را از یک سیستم قدیمی استخراج کردهام. لطفاً بدون تغییر دادن کد، وظیفه اصلی آن، ورودیها، خروجیها و هرگونه وابستگی پنهان یا Side Effect (مانند دسترسی به دیتابیس یا تغییر متغیرهای Global) را به صورت نقاط گلولهای توضیح بده."
گام دوم: ساخت پایگاه تست (Characterization Tests)
پیش از دستکاری کد، باید رفتار فعلی آن را مستند و تثبیت کنید. از هوش مصنوعی بخواهید برای ساختار موجود، تست بنویسد.
پرامپت پیشنهادی:
"بر اساس کدی که تحلیل کردی، یک مجموعه کامل از تستهای واحد (Unit Tests) با استفاده از [نام فریمورک تست، مثلاً xUnit یا JUnit] بنویس. این تستها باید شامل ورودیهای نرمال، مقادیر خالی (Null)، و حالتهای استثنایی (Edge Cases) باشند تا مطمئن شویم رفتار فعلی کد کاملاً پوشش داده شده است."
تستها را اجرا کنید و مطمئن شوید که همگی سبز (Pass) میشوند.
گام سوم: بازنویسی بازگشتی و تکاملی (Iterative Refactoring)
حالا زمان تحول است. اما این تحول باید لایه به لایه انجام شود. به عنوان مثال، ابتدا بوی کد را برطرف کنید، سپس به سراغ معماری بروید. میتوانید از هوش مصنوعی بخواهید اصول Clean Code یا الگوهای طراحی مشخصی را اعمال کند.
مثال: تفکیک منطق دسترسی به دیتابیس از منطق تجاری (Decoupling Data Access from Business Logic).
مثال: اعمال الگوی استراتژی (Strategy Pattern) به جای شرطهای if-else یا switch متوالی و طولانی.
گام چهارم: تایید صحت (Verification)
کد جدید تولیدشده توسط هوش مصنوعی را جایگزین کنید. تستهای واحدی را که در گام دوم نوشتید، مجدداً اجرا کنید. اگر تستها قرمز شدند، یعنی هوش مصنوعی رفتار منطقی سیستم را تغییر داده است. خطای تست را به هوش مصنوعی بازخورد دهید تا کد را اصلاح کند.
| پارامتر | رِفکتورینگ سنتی (دستی) | رِفکتورینگ مدرن (با کمک هوش مصنوعی) |
| سرعت درک کد | نیاز به ساعتها یا روزها بررسی خط به خط کد توسط برنامهنویس | تحلیل معنایی و خلاصهسازی ساختار در چند ثانیه |
| تولید تستهای واحد | فرآیندی خستهکننده که معمولاً توسط توسعهدهندگان نادیده گرفته میشود | تولید انبوه و سریع تستهای جامع برای سناریوهای مختلف |
| اعمال الگوهای طراحی | نیازمند تسلط بالا و تمرکز شدید برای عدم ایجاد خطا | پیشنهاد الگوهای ساختاری متعدد (مانند کپسولهسازی، تزریق وابستگی) |
| احتمال خطا | خطای انسانی ناشی از خستگی و عدم تمرکز | خطای ناشی از توهم مدل (Hallucination) یا عدم درک کانتکست بزرگ پروژه |
تفاوت یک برنامهنویس جونیور و یک مهندس سینیور در استفاده از هوش مصنوعی، نحوه گفتگو و هدایت مدل است. برای رِفکتورینگهای پیچیده، این تکنیکها حیاتی هستند:
۱. تعیین نقش دقیق (Role Prompting)
به مدل یک هویت متخصص بدهید تا خروجیهای سطحی تولید نکند.
"تو یک معمار ارشد نرمافزار با ۲۰ سال تجربه در بازنویسی سیستمهای بزرگ و مسلط به الگوهای طراحی شیءگرا و Clean Architecture هستی. کد زیر را با دیدگاه کاهش پیچیدگی سایکلوماتیک (Cyclomatic Complexity) بررسی کن..."
۲. اعمال محدودیتهای سختگیرانه (Hard Constraints)
اگر محدودیتها را مشخص نکنید، هوش مصنوعی ممکن است از کتابخانههایی استفاده کند که در پروژه شما وجود ندارند.
"...کد بازنویسیشده نباید از هیچ کتابخانه جانبی جدیدی استفاده کند. حتماً از قابلیتهای بومی داتنت ۸ استفاده کن و ساختار متد را به صورت کاملاً ناهمگام (Async/Await) درآور."
۳. تکنیک بازنویسی گامبهگام (Chain of Thought)
از مدل بخواهید ابتدا استراتژی خود را توضیح دهد، سپس کد را بنویسد. این کار خطای مدل را به شدت کاهش میدهد.
"ابتدا مشکلات ساختاری کد زیر را لیست کن و توضیح بده برای بهبود آن چه مراحلی را پیشنهاد میکنی. تا زمانی که من تایید نکردهام، کد جدید را تولید نکن."
استفاده نابجا از هوش مصنوعی در محیطهای عملیاتی میتواند فاجعهبار باشد. به عنوان یک مهندس نرمافزار، باید از تلههای زیر آگاه باشید:
تله اول: توهم هوش مصنوعی (Hallucination)
مدلهای زبانی گاهی متدها یا کلاسهایی را از خود ابداع میکنند که وجود خارجی ندارند یا در پلتفرم مقصد رفتار متفاوتی نشان میدهند. بررسی خط به خط کد تولیدشده توسط انسان، یک ضرورت غیرقابل حذف است.
تله دوم: از دست رفتن قوانین تجاری ظریف (Subtle Business Rules)
کدهای قدیمی معمولاً پر از «وصلههای ناجور» یا هکهایی هستند که برای برطرف کردن باگهای خاص سیستمهای جانبی نوشته شدهاند. هوش مصنوعی ممکن است این خطوط را به عنوان "کد کثیف" شناسایی کرده و حذف کند، در حالی که حذف آنها باعث از کار افتادن ارتباط سیستم با یک کلاینت قدیمی میشود.
تله سوم: نشت اطلاعات و حریم خصوصی (Data Privacy)
ارسال کدهای انحصاری و محرمانه شرکت به سرورهای عمومی هوش مصنوعی (مانند نسخههای رایگان ChatGPT) میتواند قوانین حریم خصوصی و امنیت داده را نقض کند.
راهکار امنیتی: برای پروژههای حساس سازمانی، حتماً از ابزارهای Enterprise (که دادهها را برای آموزش مدل ذخیره نمیکنند) یا مدلهای محلی و متنباز (مانند Llama 3 یا CodeLlama) روی سرورهای داخلی شرکت استفاده کنید.
برای اینکه لیدر این بازی باشید و نه مغلوب آن، این اصول را در سازمان یا پروژههای شخصی خود نهادینه کنید:
هوش مصنوعی کمکخلبان است، شما خلبان هستید: مسئولیت نهایی خط به خط کدی که به برانچ main یا محیط Production مرج میشود، با شماست، نه هوش مصنوعی.
رِفکتورینگهای کوچک و متوالی بر رِفکتورینگهای بزرگ ترجیح دارند: تغییرات را به تکههای بسیار کوچک (Atomic Commits) تقسیم کنید و پس از هر تغییر، تستها را اجرا کنید.
کد تمیز، فقط کدی نیست که کار میکند: کد بازنویسیشده باید توسط دیگر اعضای تیم نیز به راحتی خوانده و درک شود. اگر هوش مصنوعی کدی بسیار پیچیده اما بهینه تولید کرد، از او بخواهید آن را سادهتر و خواناتر کند.
دستیارهای هوش مصنوعی، موازنه قدرت را در مواجهه با کدهای قدیمی تغییر دادهاند. کارهایی که پیش از این هفتهها زمان میبرد و سرشار از استرس و خطاهای پیشبینینشده بود، اکنون با هدایت یک مهندس باخبر و متبحر و با بازوهای پردازشی هوش مصنوعی، میتواند در چند ساعت و با ضریب اطمینان بسیار بالاتر انجام شود.
هوش مصنوعی ما را از کارهای تکراری و فرساینده (مانند نوشتن بویلرپلیتها و تستهای روتین) آزاد میکند تا بتوانیم تمرکز اصلی خود را روی معماری سیستم، طراحی الگوهای کلان و حل مسائل پیچیده تجاری بگذاریم. بازنویسی کدهای قدیمی با کمک هوش مصنوعی، یک انتخاب نیست؛ بلکه یک مهارت حیاتی برای مهندسان نرمافزار مدرن است که مرز بین سیستمهای فرسوده و نرمافزارهای چابک و مقیاسپذیر آینده را تعیین میکند.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.