
پادشاهِ کُدنویسا شو!
پایگاههای داده SQL بر پایه مدل رابطهای (Relational) بنا شدهاند و از یک شمای (Schema) سفت و سخت پیروی میکنند. این ویژگی برای سناریوهایی که در آن دادهها دارای ویژگیهای ثابت و از پیش تعریف شده هستند (مانند دادههای مالی یا جداول آماری)، ایدهآل است. در آموزش مدلهای یادگیری ماشین سنتی (مانند Linear Regression)، SQL به دلیل یکپارچگی دادهای (ACID) و دقت بالا، نقش کلیدی ایفا میکند.
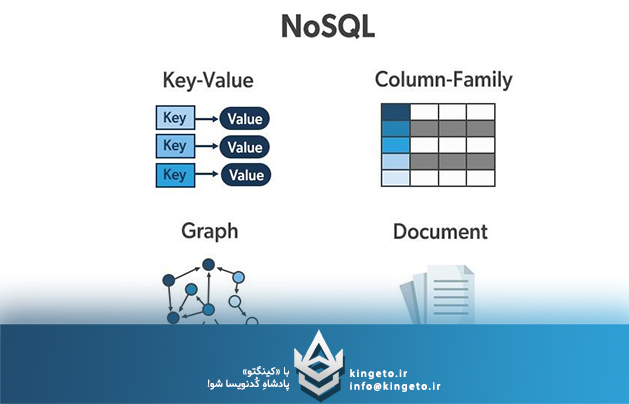
در مقابل، مدلهای هوش مصنوعی مدرن، بهویژه در حوزههای پردازش زبان طبیعی (NLP) و بینایی ماشین، با حجم عظیمی از دادههای غیرساختاریافته مانند متن، تصویر و ویدیو سروکار دارند. در اینجا NoSQL وارد میدان میشود. پایگاههای داده سندمحور (Document-oriented) یا کلید-مقدار (Key-Value) به مهندسان اجازه میدهند بدون درگیری با محدودیتهای Schema، دادههای متنوع را با سرعت بالا ذخیره کنند. برای مثال، در آموزش یک مدل ترنسفورمر، انعطافپذیری NoSQL در مدیریت متادیتای متغیر، یک مزیت استراتژیک محسوب میشود.
آموزش مدلهای عمیق (Deep Learning) مستلزم پردازش ترابایتها داده است. پایگاههای داده SQL بهطور سنتی بر مقیاسپذیری عمودی (Vertical Scaling) یا افزایش منابع یک سرور واحد تکیه دارند. اگرچه تکنولوژیهایی مانند Sharding برای SQL معرفی شدهاند، اما مدیریت آنها در مقیاسهای بسیار بزرگ هوش مصنوعی میتواند به پیچیدگیهای معماری شدیدی منجر شود که نگهداری سیستم را دشوار میکند.
پایگاههای داده NoSQL با هدف مقیاسپذیری افقی (Horizontal Scaling) طراحی شدهاند. معماری توزیعشده (Distributed) در سیستمهایی مثل Cassandra یا MongoDB اجازه میدهد با افزودن نودهای ارزانقیمت به کلاستر، ظرفیت ذخیرهسازی و قدرت پردازشی را به صورت خطی افزایش داد. برای پروژههای AI که با جریانهای دادهای (Data Streams) لحظهای سروکار دارند، توانایی NoSQL در توزیع بار کاری و تحمل خطا (Fault Tolerance)، پایداری فرآیند آموزش را تضمین میکند.
فرآیند توسعه هوش مصنوعی یک مسیر خطی نیست؛ مدلها مدام تغییر میکنند و ویژگیهای جدید (Features) به دادههای آموزشی اضافه میشوند. در پایگاههای داده SQL، هرگونه تغییر در ساختار داده نیازمند اجرای دستورات ALTER TABLE است که در جداول حجیم میتواند باعث توقف موقت سیستم (Downtime) شود. این صلبیت ساختاری میتواند سرعت آزمایش و خطای تیمهای دیتا ساینس را کاهش دهد.
پایگاههای داده NoSQL از رویکرد Schema-on-Read استفاده میکنند. این یعنی شما میتوانید دادهها را به هر شکلی که هستند ذخیره کرده و ساختاردهی را در زمان فراخوانی انجام دهید. این ویژگی برای "مهندسی ویژگی" (Feature Engineering) بسیار حیاتی است. وقتی محققان هوش مصنوعی تصمیم میگیرند پارامتر جدیدی را به دیتاست آموزشی اضافه کنند، در سیستمهای NoSQL نیازی به بازسازی کل دیتابیس نیست. این انعطافپذیری، فاصله زمانی بین فرضیه تا پیادهسازی مدل را به حداقل میرساند.
اگرچه بحث بین SQL و NoSQL همچنان داغ است، اما ظهور مدلهای زبانی بزرگ (LLM) رده جدیدی از ذخیرهسازی را ایجاب کرده است: Vector Databases. در حالی که SQL در جستجوی دقیق مقادیر عالی است و NoSQL در مدیریت اسناد، پایگاههای داده برداری برای ذخیره و جستجوی "امبدینگها" (Embeddings) بهینهسازی شدهاند.
در هوش مصنوعی مدرن، دادهها (متن، تصویر و غیره) به بردارهای عددی در فضاهای چندبعدی تبدیل میشوند. پایگاههای دادهای مانند Pinecone، Milvus یا افزونه PGVector در PostgreSQL، سعی دارند شکاف بین ساختارهای سنتی و نیازهای مدرن را پر کنند. انتخاب بین SQL و NoSQL در اینجا به این بستگی دارد که آیا به یک سیستم چندمنظوره نیاز دارید یا یک موتور جستجوی شباهت تخصصی. برای سیستمهای RAG (تولید با بازیابی تقویتشده)، تلفیق قابلیتهای کوئرینویسی SQL با قدرت جستجوی برداری، معماری قدرتمندی را رقم میزند.
انتخاب نهایی بین SQL و NoSQL برای دادههای آموزشی AI، به "ماهیت داده" و "نیازهای عملیاتی" بستگی دارد. اگر پروژه شما بر پایه دادههای جدولی با روابط پیچیده بین موجودیتهاست و یکپارچگی تراکنشی اولویت اول شماست، SQL (مانند SQL Server یا PostgreSQL) همچنان پادشاه است. این سیستمها ابزارهای تحلیل آماری قدرتمندی دارند که قبل از شروع آموزش مدل، برای پاکسازی دادهها بسیار مفید هستند.
اما اگر با دادههای حجیم، متنوع و با نرخ ورود بالا (High Ingestion Rate) روبرو هستید، NoSQL انتخاب منطقیتری است. برای مثال، در سیستمهای توصیهگر (Recommendation Systems) که رفتار کاربران را به صورت لحظهای رصد میکنند، سرعت نوشتن (Write Throughput) در NoSQL برتری محسوسی دارد. در نهایت، بسیاری از سازمانهای پیشرو در حوزه AI به سمت "معماری چندگانه" (Polyglot Persistence) حرکت کردهاند؛ استفاده از SQL برای متادیتای ساختاریافته و NoSQL برای ذخیرهسازی بدنه اصلی دادههای آموزشی.
| معیار | SQL | NoSQL |
| نوع داده | ساختاریافته (Structured) | غیرساختاریافته / نیمهساختاریافته |
| مقیاسپذیری | عمودی (Vertical) | افقی (Horizontal) |
| یکپارچگی | ACID (سختگیرانه) | BASE (انعطافپذیر) |
| سرعت توسعه | پایینتر (به دلیل Schema) | بالاتر (Schema-less) |
| مورد استفاده AI | مدلهای آماری، دادههای مالی | یادگیری عمیق، NLP، پردازش تصویر |

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.