
پادشاهِ کُدنویسا شو!

برای توسعهدهندگان اکوسیستم داتنت ، ورود به دنیای هوش مصنوعی و یادگیری ماشین در گذشته نیازمند تغییر زبان به پایتون یا آر بود. اما مایکروسافت با ارائه ML.NET این مرز را از بین برد. ML.NET یک فریمورک متنباز و چندپلتفرمی است که به مهندسان سیشارپ اجازه میدهد بدون خروج از اکوسیستم آشنای خود، مدلهای یادگیری ماشین با مقیاس تولید (Production-ready) بسازند، آموزش دهند و مستقر کنند.
در این مقاله تخصصی، معماری، ریاضیات پایه و پیادهسازی گامبهگام یک سیستم توصیهگر پیشرفته را با استفاده از ML.NET و الگوریتم Matrix Factorization بررسی خواهیم کرد.
به طور کلی، سیستمهای توصیهگر به سه دسته اصلی تقسیم میشوند:
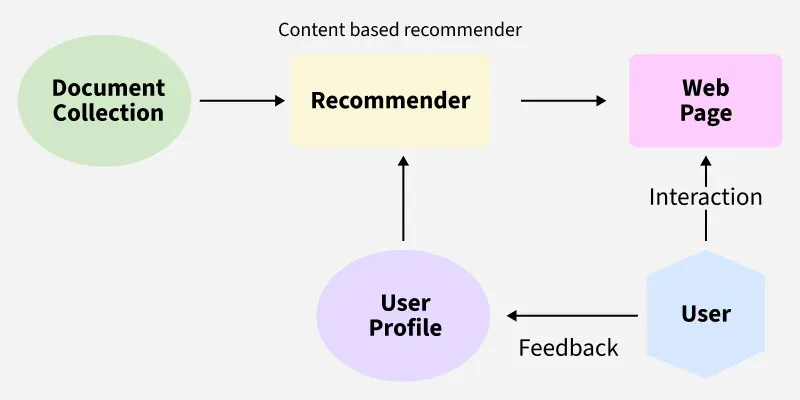
فیلترینگ مبتنی بر محتوا (Content-Based Filtering): در این روش، ویژگیهای آیتمها (مثلاً ژانر فیلم، کارگردان، کلمات کلیدی) با پروفایل علاقهمندی کاربر مقایسه میشود.
فیلترینگ مشارکتی (Collaborative Filtering): این روش بر این فرض استوار است که اگر کاربر A و کاربر B در گذشته رفتارهای مشابهی داشتهاند (مثلاً به فیلمهای مشترکی امتیاز بالا دادهاند)، در آینده نیز نظرات مشابهی خواهند داشت. این روش نیازی به دانستن ویژگیهای ذاتی آیتمها ندارد.
سیستمهای ترکیبی (Hybrid Systems): ترکیبی از دو روش بالا برای پوشش نقاط ضعف یکدیگر.
در ML.NET، قدرتمندترین ابزار برای ساخت سیستمهای توصیهگر، رویکرد فیلترینگ مشارکتی با استفاده از تکینیک تجزیه ماتریس (Matrix Factorization) است.
ریاضیات تجزیه ماتریس (Matrix Factorization)
فرض کنید یک ماتریس بزرگ R داریم که در آن سطرها کاربران (U) و ستونها آیتمها (I) هستند. هر سلول R_{u,i} نشاندهنده امتیازی است که کاربر u به آیتم i داده است. این ماتریس در دنیای واقعی بسیار تنک (Sparse) است، زیرا هر کاربر تنها به بخش کوچکی از آیتمها بازخورد نشان میدهد.
هدف Matrix Factorization این است که این ماتریس تنک R را به دو ماتریس با ابعاد بسیار کوچکتر (رتبه پایین) تجزیه کند:
ماتریس کاربرها (P) با ابعاد U \times k
ماتریس آیتمها (Q) با ابعاد I \times k
در اینجا k نشاندهنده ویژگیهای پنهان (Latent Features) است. این ویژگیها به صورت صریح تعریف نمیشوند (مثلاً در مورد فیلم، ممکن است ترکیبی پنهان از میزان اکشن بودن، تم دراماتیک و لحن دیالوگها باشد که مدل خود به خود کشف کرده است).
پیشبینی امتیاز کاربر u به آیتم i از طریق ضرب داخلی (Dot Product) دو بردار پنهان متناظر محاسبه میشود:
\hat{R}_{u,i} = P_u \cdot Q_i^T = \sum_{m=1}^{k} P_{u,m} Q_{i,m}
برای بهینهسازی این ماتریسها و به حداقل رساندن خطای پیشبینی، ML.NET از الگوریتم Stochastic Dual Coordinate Ascent (SDCA) یا روشهای مشتقشده از Stochastic Gradient Descent (SGD) استفاده میکند تا تابع زیان (Loss Function) زیر را مینیمم کند:
\min_{P,Q} \sum_{(u,i) \in R} (R_{u,i} - P_u Q_i^T)^2 + \lambda (||P_u||^2 + ||Q_i||^2)
که در آن \lambda پارامتر منظمسازی (Regularization) برای جلوگیری از بیشبرازش (Overfitting) است.
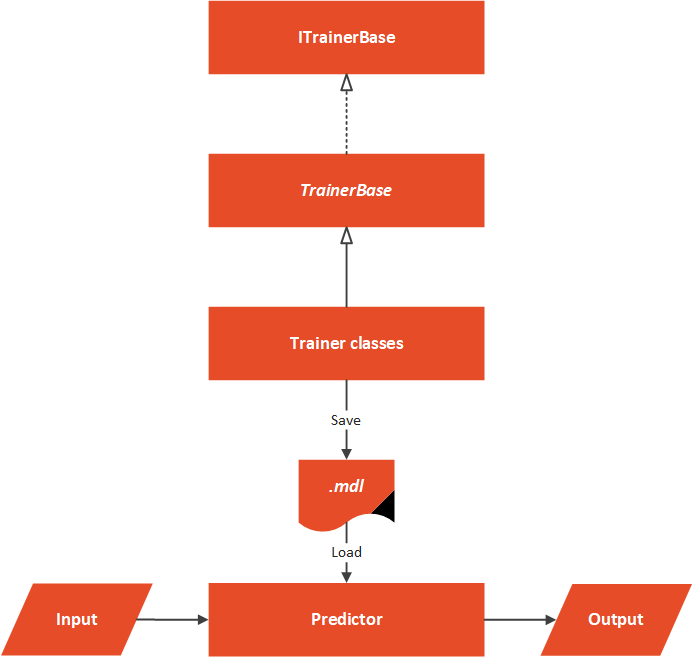
در یک سیستم نرمافزاری Enterprise، نباید کدهای مربوط به یادگیری ماشین را با کدهای لایه کنترلر یا لایک دسترسی به داده (Data Access) ترکیب کرد. معماری پیشنهادی برای این سیستم به صورت زیر بخشبندی میشود:
Core / Domain: شامل Entityها و اینترفیسهای اصلی سیستم.
Infrastructure: شامل پیادهسازی دسترسی به دیتابیس (EF Core) و عملیاتهای ذخیره و بارگذاری مدل ML.NET.
ML.Engine: یک پروژه مجزا (یا کلاس لایبرری) که وظیفه Pipeline Pipeline، آموزش (Training)، ارزیابی (Evaluation) و تولید خروجی مدل را بر عهده دارد.
API / Presentation: نقطهای که از مدل آموزشدیده از طریق مکانیزم PredictionEnginePool استفاده میکند تا با عملکرد بالا (High Performance) پاسخ درخواستهای کاربران را بدهد.
در این سناریو، ما یک سیستم توصیهگر فیلم بر اساس امتیازدهی کاربران میسازیم.
گام اول: تعریف ساختارهای داده (Data Models)
ابتدا باید ساختار دادههای ورودی و خروجی مدل را مشخص کنیم. در لایه ML.Engine دو کلاس سیشارپ تعریف میکنیم:
using Microsoft.VisualBasic.FileIO;
using Microsoft.ML.Data;
namespace RecommenderSystem.ML.Engine.DataModels
{
// این کلاس نشاندهنده ساختار دادههای ورودی برای آموزش مدل است
public class MovieRating
{
[LoadColumn(0)]
public float UserId { get; set; }
[LoadColumn(1)]
public float MovieId { get; set; }
[LoadColumn(2)]
public float Label { get; set; } // امتیازی که کاربر داده است
}
// این کلاس ساختار خروجی پیشبینی را مشخص میکند
public class MovieRatingPrediction
{
public float Label { get; set; }
public float Score { get; set; } // امتیاز پیشبینی شده توسط مدل
}
}
نکته تخصصی: ویژگی [LoadColumn] زمانی استفاده میشود که دادهها را مستقیم از فایل CSV بارگذاری میکنید. فریمورک ML.NET از برچسب Label به عنوان متغیر هدف (Target) برای پیشبینی استفاده میکند. همچنین فیلدهای کلیدی در الگوریتم Matrix Factorization باید از نوع Single (float) باشند.
گام دوم: طراحی خط لوله آموزش (Training Pipeline)
اکنون کلاسی با نام ModelTrainer ایجاد میکنیم که مسئولیت بارگذاری دادهها، ساخت خط لوله پردازشی، آموزش و ذخیره مدل را بر عهده دارد.
using System;
using System.IO;
using Microsoft.ML;
using Microsoft.ML.Trainers;
using RecommenderSystem.ML.Engine.DataModels;
namespace RecommenderSystem.ML.Engine
{
public class ModelTrainer
{
private readonly MLContext _mlContext;
public ModelTrainer()
{
// مقداردهی اولیه به MLContext با یک Seed ثابت برای تکرارپذیری نتایج
_mlContext = new MLContext(seed: 42);
}
public void TrainAndSaveModel(string trainingDataPath, string modelSavePath)
{
// ۱. بارگذاری دادهها
IDataView trainingDataView = _mlContext.Data.LoadFromTextFile<MovieRating>(
path: trainingDataPath,
hasHeader: true,
separatorChar: ',');
// ۲. پیشپردازش دادهها و تبدیل کلیدها به اسلاتهای عددی (MapValueToKey)
// الگوریتم Matrix Factorization نیاز دارد که شناسه کاربر و آیتم به فرمت KeyType تبدیل شوند.
var dataProcessPipeline = _mlContext.Transforms.Conversion
.MapValueToKey(outputColumnName: "UserIdEncoded", inputColumnName: nameof(MovieRating.UserId))
.Append(_mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "MovieIdEncoded", inputColumnName: nameof(MovieRating.MovieId)));
// ۳. انتخاب و تنظیم ابرپارامترهای (Hyperparameters) الگوریتم
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "UserIdEncoded",
MatrixRowIndexColumnName = "MovieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20, // تعداد دورهای آموزش
ApproximationRank = 100, // تعداد ویژگیهای پنهان (Latent Features)
LearningRate = 0.1f, // نرخ یادگیری
LossFunction = MatrixFactorizationTrainer.LossFunctionType.SquareLossOneClass
};
var trainer = _mlContext.Recommendation().Trainers.MatrixFactorization(options);
// ۴. متصل کردن پروسسها و الگوریتم به یک خط لوله واحد
var trainingPipeline = dataProcessPipeline.Append(trainer);
// ۵. آموزش مدل (Fit)
Console.WriteLine("=== در حال آموزش مدل یادگیری ماشین... ===");
ITransformer model = trainingPipeline.Fit(trainingDataView);
Console.WriteLine("=== آموزش مدل با موفقیت به پایان رسید ===");
// ۶. ذخیره مدل به صورت فایل zip برای استفاده در محیط Production
_mlContext.Model.Save(model, trainingDataView.Schema, modelSavePath);
Console.WriteLine($"مدل با موفقیت در مسیر روبرو ذخیره شد: {modelSavePath}");
}
}
}
گام سوم: ارزیابی مدل (Evaluation)
پس از آموزش مدل، نباید آن را بدون ارزیابی دقیق وارد لایه عملیاتی کرد. برای ارزیابی مدلهای رگرسیون و سیستمهای توصیهگر، از معیارهایی چون Root Mean Squared Error (RMSE) و R-Squared (R^2) استفاده میشود.
هرچه میزان RMSE به صفر نزدیکتر باشد، دقت مدل بالاتر است.
public void EvaluateModel(string testDataPath, string modelPath)
{
IDataView testDataView = _mlContext.Data.LoadFromTextFile<MovieRating>(path: testDataPath, hasHeader: true, separatorChar: ',');
// بارگذاری مدل ذخیره شده
ITransformer model = _mlContext.Model.Load(modelPath, out var modelInputSchema);
// اعمال مدل روی دادههای تست
IDataView predictions = model.Transform(testDataView);
// ارزیابی عملکرد مدل
var metrics = _mlContext.Recommendation().Evaluate(predictions, labelColumnName: "Label", scoreColumnName: "Score");
Console.WriteLine($"=== نتایج ارزیابی مدل ===");
Console.WriteLine($"Root Mean Squared Error (RMSE): {metrics.RootMeanSquaredError:F4}");
Console.WriteLine($"Mean Absolute Error (MAE): {metrics.MeanAbsoluteError:F4}");
Console.WriteLine($"R-Squared: {metrics.RSquared:F4}");
}
یکی از چالشهای رایج در استفاده از مدلهای یادگیری ماشین در پروژههای وب، عدم Thread-Safe بودن شیء PredictionEngine در ML.NET است. ساختن یک نمونه جدید از این شیء برای هر Request، سربار (Overhead) بسیار سنگینی به حافظه و CPU وارد میکند و کارایی سیستم را به شدت کاهش میدهد.
راهکار استاندارد مایکروسافت، استفاده از PredictionEnginePool است. این ابزار از مکانیزم Object Pooling استفاده کرده و مدیریت چرخهحیات نمونهها را به صورت کاملاً Thread-Safe و بهینه به عهده میگیرد.
مرحله ۱: ثبت در کانتینر الگو تزریق وابستگی (Dependency Injection)
در فایل Program.cs وب سرویس خود، افزونه متناظر را ریجستر کنید:
using Microsoft.Extensions.ML;
using RecommenderSystem.ML.Engine.DataModels;
var builder = WebApplication.CreateBuilder(args);
// اضافه کردن لایبرری PredictionEnginePool به دایرکتوری سرویسها
// مدل را از فایل ذخیره شده لود میکند
builder.Services.AddPredictionEnginePool<MovieRating, MovieRatingPrediction>()
.FromFile(modelName: "MovieRecommenderModel", filePath: "Models/movie_factorization_model.zip", watchForChanges: true);
builder.Services.AddControllers();
var app = builder.Build();
app.UseRouting();
app.MapControllers();
app.Run();
نکته کلیدی: پارامتر watchForChanges: true به این معنی است که اگر شما مدل را مجدداً آموزش دهید و فایل .zip را جایگزین کنید، PredictionEnginePool به صورت خودکار و بدون نیاز به ریاستارت کردن وبسرور، مدل جدید را بارگذاری (Hot-Reload) میکند.
مرحله ۲: پیادهسازی کنترلر API
اکنون کنترلری ایجاد میکنیم تا عملیات پیشبینی امتیاز یک فیلم برای یک کاربر خاص را انجام دهد.
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.ML;
using RecommenderSystem.ML.Engine.DataModels;
namespace RecommenderSystem.Api.Controllers
{
[ApiController]
[Route("api/[controller]")]
public class RecommendationController : ControllerBase
{
private readonly PredictionEnginePool<MovieRating, MovieRatingPrediction> _predictionEnginePool;
public RecommendationController(PredictionEnginePool<MovieRating, MovieRatingPrediction> predictionEnginePool)
{
_predictionEnginePool = predictionEnginePool;
}
/// <summary>
/// پیشبینی میزان علاقه یک کاربر به یک فیلم مشخص
/// </summary>
[HttpGet("predict")]
public ActionResult<float> PredictRating([FromQuery] float userId, [FromQuery] float movieId)
{
var sample = new MovieRating
{
UserId = userId,
MovieId = movieId
};
// استفاده از پول برای پیشبینی سریع و Thread-Safe
var prediction = _predictionEnginePool.Predict(modelName: "MovieRecommenderModel", example: sample);
// محدود کردن امتیاز در بازه منطقی سیستم (مثلاً 1 تا 5 ستاره)
float finalScore = Math.Clamp(prediction.Score, 1.0f, 5.0f);
return Ok(new { UserId = userId, MovieId = movieId, PredictedRating = finalScore });
}
}
}
پیادهسازی ابتدایی مدل یادگیری ماشین تنها بخشی از فرآیند است. در محیطهای Enterprise با سناریوهای پیچیدهتری روبرو میشوید که نیازمند طراحی استراتژیک هستند:
۱. مسئله شروع سرد (Cold Start Problem)
وقتی یک کاربر جدید ثبتنام میکند یا یک آیتم جدید به سیستم اضافه میشود، هیچ تاریخچه یا امتیازی برای آنها وجود ندارد. در این حالت، فیلترینگ مشارکتی کارایی ندارد.
راهکار: سیستم را به صورت Hybrid طراحی کنید. برای کاربران جدید، محبوبترین یا ترندترین آیتمها (Popularity-based) را نمایش دهید، یا در زمان ثبتنام، علایق اولیه آنها را بپرسید. برای آیتمهای جدید، از رویکرد مبتنی بر محتوا (Content-Based) استفاده کنید تا آیتم را بر اساس شباهت متنی یا ژانری به آیتمهای قدیمیتر لینک کنید.
۲. بروزرسانی مداوم مدل (Continuous Retraining)
رفتار کاربران به مرور زمان تغییر میکند. مدلی که امروز عالی کار میکند، ممکن است شش ماه دیگر خروجی نامناسبی داشته باشد.
راهکار: ایجاد یک سرویس دورهای (Background Worker با استفاده از IHostedService یا Azure Functions) که دادههای جدید را در ساعات کممصرف شبکه جمعآوری کرده، فرآیند TrainAndSaveModel را مجدداً اجرا کند. به دلیل استفاده از قابلیت watchForChanges در وبسرور، مدل جدید بدون Downtime جایگزین میشود.
۳. بهینهسازی عملکرد حافظه (Memory Optimization)
اگر تعداد کاربران و آیتمهای شما به میلیونها ردیف برسد، متد LoadFromTextFile ممکن است تمام حافظه RAM سرور را اشغال کند.
راهکار: از متد LoadFromEnumerable استفاده کنید و دادهها را به صورت Stream یا پارتبندی شده (Paging) از دیتابیس (مانند SQL Server با ایندکسهای Columnstore یا پایگاه دادههای NoSQL) بخوانید تا کل کلانداده به طور همزمان وارد حافظه موقت نشود.
فریمورک ML.NET به مهندسان نرمافزار داتنت این قدرت را میدهد که بدون نیاز به جابجایی بین پلتفرمها و زبانهای مختلف، سیستمهای هوش مصنوعی با کارایی بسیار بالا ایجاد کنند. با استفاده از الگوریتم Matrix Factorization، پیادهسازی الگوهای معماری تمیز و بهرهگیری از PredictionEnginePool در ASP.NET Core، میتوان سیستمهای توصیهگر مقیاسپذیر، سریع و آماده برای محیطهای تجاری بزرگ ایجاد کرد که تجربه کاربری را به طور چشمگیری ارتقا میدهند.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.