
پادشاهِ کُدنویسا شو!
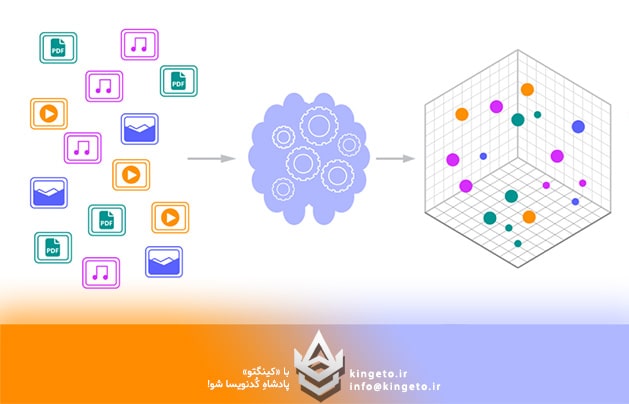
مدلهای هوش مصنوعی مولد بر روی حجم عظیمی از دادههای اینترنت تا یک زمان مشخص (Knowledge Cutoff) آموزش دیدهاند. با این حال، آنها دو محدودیت بزرگ دارند:
توهم (Hallucination): زمانی که مدل پاسخ دقیقی ندارد، ممکن است پاسخی کاملاً اشتباه اما متقاعدکننده تولید کند.
عدم دسترسی به دادههای خصوصی یا تازه: یک LLM استاندارد از اسناد داخلی شرکت شما یا اخبار نیم ساعت پیش اطلاعی ندارد.
اینجاست که دیتابیسهای برداری وارد صحنه میشوند تا به عنوان یک منبع دانش خارجی و قابل جستجو، اطلاعات لازم را در لحظه به مدل برسانند.
دیتابیس برداری نوعی پایگاه داده است که اطلاعات را نه به صورت متن یا عدد ساده، بلکه به صورت بردارهای ریاضی (Vectors) ذخیره میکند.
مفهوم امبدینگ (Embedding)
هر دادهای (متن، تصویر، صدا) میتواند توسط مدلهای یادگیری ماشین به رشتهای از اعداد تبدیل شود که به آن Embedding میگویند. این اعداد نشاندهنده «معنا» و «مفهوم» آن داده در یک فضای چندبعدی هستند.
در این فضا، کلماتی که معنای نزدیکی دارند (مثلاً «گربه» و «بچه گربه»)، بردارهایی دارند که در فضای ریاضی به هم نزدیکترند، در حالی که کلماتی مثل «گربه» و «آسمانخراش» از هم دور هستند.
تفاوت با دیتابیسهای سنتی (Relational vs. Vector)
| ویژگی | دیتابیس سنتی (SQL) | دیتابیس برداری |
| نوع جستجو | تطبیق دقیق کلیدواژه (Keyword Match) | جستجوی شباهت معنایی (Semantic Similarity) |
| ساختار داده | جداول، ردیفها و ستونها | بردارهای پربعد (High-dimensional Vectors) |
| خروجی | نتایج قطعی (بله/خیر) | نتایج احتمالی (مشابهترینها) |
مهمترین کاربرد دیتابیسهای برداری در هوش مصنوعی مولد، تکنولوژی RAG (Retrieval-Augmented Generation) یا «تولید تقویتشده با بازیابی» است.
فرآیند RAG چگونه کار میکند؟
ذخیرهسازی: تمام اسناد و دانش سازمان به بردار تبدیل شده و در دیتابیس برداری ذخیره میشوند.
پرسش کاربر: وقتی کاربر سوالی میپرسد، آن سوال هم به بردار تبدیل میشود.
بازیابی (Retrieval): دیتابیس برداری سریعاً مرتبطترین تکههای اطلاعات را بر اساس شباهت ریاضی پیدا میکند.
تولید (Generation): این اطلاعات استخراج شده به همراه سوال اصلی به LLM فرستاده میشود. حالا مدل با داشتن دانش کافی، پاسخی دقیق و مستند ارائه میدهد.
غلبه بر محدودیت Context Window
کاهش هزینهها و افزایش سرعت
ج) امنیت و حریم خصوصی
در دیتابیسهای معمولی، ما به دنبال برابری هستیم ($x = y$). در دیتابیس برداری، ما به دنبال نزدیکی هستیم. این کار معمولاً از طریق فرمولهای ریاضی مانند تشابه کسینوسی (Cosine Similarity) انجام میشود:
$$\text{similarity} = \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|}$$
این فرمول به دیتابیس اجازه میدهد حتی اگر کلمات دقیقاً یکسان نباشند (مثلاً یکی از «ماشین» و دیگری از «خودرو» استفاده کرده باشد)، متوجه شباهت معنایی آنها بشود.
اگر قصد پیادهسازی چنین سیستمی را داشته باشید، گزینههای محبوبی وجود دارند:
Pinecone: یک دیتابیس کاملاً ابری (SaaS) که کار با آن بسیار ساده و مقیاسپذیر است.
Milvus: یک گزینه متنباز (Open-source) و بسیار قدرتمند برای پردازش میلیاردها بردار.
Weaviate: دیتابیسی که تمرکز زیادی روی جستجوی معنایی و اشیاء دارد.
Chroma: گزینهای سبک و عالی برای توسعهدهندگانی که میخواهند سریعاً روی سیستم محلی خود پروژه را شروع کنند.
با وجود تمام مزایا، استفاده از دیتابیسهای برداری بدون چالش نیست:
انتخاب مدل امبدینگ: کیفیت جستجو مستقیماً به مدلی بستگی دارد که متن را به بردار تبدیل میکند.
نفرین ابعاد (Curse of Dimensionality): با افزایش ابعاد بردارها، محاسبات پیچیدهتر و گاهی دقت کمتر میشود.
هزینه حافظه: ذخیرهسازی میلیونها بردار در حافظه RAM (برای سرعت بالا) میتواند پرهزینه باشد.
دیتابیسهای برداری از یک ابزار جانبی به مغز متفکر سیستمهای AI تبدیل شدهاند. آنها واسطی هستند که دنیای دادههای نامنظم (متن، تصویر و ویدیو) را برای مدلهای هوش مصنوعی قابل فهم و قابل جستجو میکنند. در آینده، شاهد ادغام بیشتر این دیتابیسها با دیتابیسهای سنتی خواهیم بود تا سیستمهایی ساخته شوند که هم در محاسبات دقیق عددی و هم در درک مفاهیم انسانی بینقص عمل کنند.
اگر به دنبال ساخت یک چتبات هوشمند، سیستم توصیهگر یا ابزار تحلیل اسناد هستید، یادگیری و استفاده از یک دیتابیس برداری دیگر یک انتخاب نیست، بلکه یک ضرورت است.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.