
پادشاهِ کُدنویسا شو!

بسیاری از توسعهدهندگان با Task و async/await برای مدیریت عملیات ناهمزمان، بهویژه در سناریوهای I/O-bound (مانند درخواستهای وب یا کار با پایگاه داده)، آشنا هستند. این ابزارها برای جلوگیری از بلاک شدن نخ اصلی و بهبود پاسخدهی برنامه فوقالعادهاند. با این حال، زمانی که با سناریوهای پیچیدهتر پردازش داده سروکار داریم—جایی که دادهها باید از چندین مرحله عبور کنند، با درجات مختلفی از موازیسازی پردازش شوند و بهطور ایمن بین وظایف مختلف جابجا شوند—async/await بهتنهایی کافی نیست.
اینجاست که TPL Dataflow با الهام از مدل اکتور (Actor Model) وارد میدان میشود. در این مدل، واحدهای مستقل و ایزولهای به نام "اکتور" (در اینجا "بلاک") از طریق ارسال پیام با یکدیگر ارتباط برقرار میکنند. هر بلاک وظیفه مشخصی دارد، پیامها را از ورودی دریافت کرده، پردازش میکند و نتیجه را به خروجی ارسال میکند. این رویکرد چندین مزیت اساسی دارد:
ایزولهسازی وضعیت (State Isolation): هر بلاک میتواند وضعیت داخلی خود را مدیریت کند و نیازی به قفلها (Locks) و مکانیزمهای پیچیده همگامسازی برای دسترسی به دادههای مشترک نیست. این امر خطر بروز شرایط رقابتی (Race Conditions) و بنبست (Deadlocks) را به شدت کاهش میدهد.
وضوح و خوانایی کد: منطق برنامه به مراحل کوچکتر و قابل مدیریت تقسیم میشود. به جای نوشتن کدهای تودرتو و پیچیده برای مدیریت وظایف، شما یک گراف یا خط لوله (Pipeline) از بلاکها را تعریف میکنید که جریان داده را به وضوح نمایش میدهد.
کنترل دقیق بر جریان داده: شما میتوانید نحوه بافر شدن پیامها، درجه موازیسازی هر مرحله و نحوه اتصال بلاکها به یکدیگر را به سادگی پیکربندی کنید.
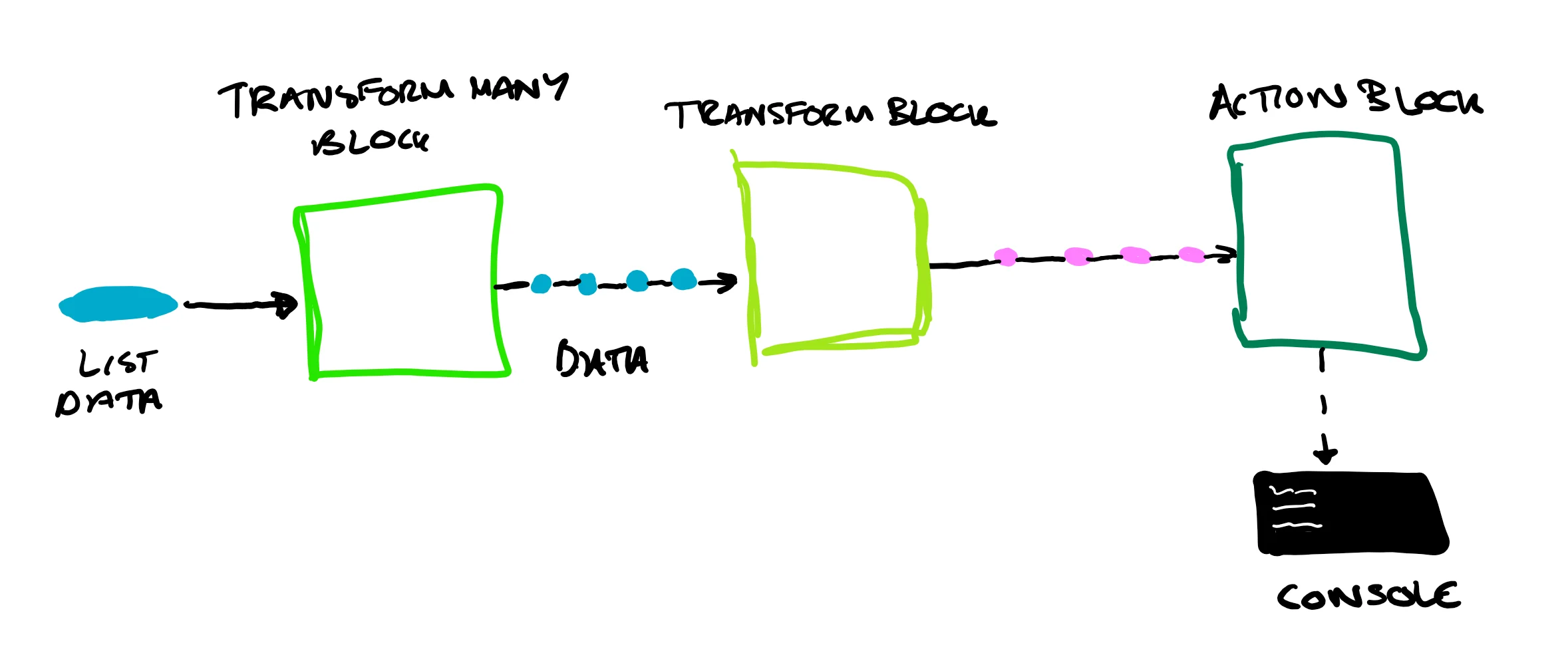
دو الگوی معماری قدرتمند که پیادهسازی آنها با TPL Dataflow بسیار ساده میشود، خط لوله و تولیدکننده-مصرفکننده هستند.
الگوی خط لوله (Pipeline Pattern)
تصور کنید فرآیندی برای پردازش تصاویر دارید: خواندن تصویر از دیسک، تغییر اندازه، اعمال یک فیلتر و در نهایت ذخیره آن. هر یک از این مراحل میتواند یک بلاک در خط لوله TPL Dataflow باشد:
TransformManyBlock<string, byte[]>: لیستی از مسیرهای فایل را دریافت کرده و محتوای بایت هر فایل را به عنوان خروجی تولید میکند.
TransformBlock<byte[], Bitmap>: آرایه بایت را به یک شیء تصویر تبدیل میکند.
TransformBlock<Bitmap, Bitmap>: فیلتر مورد نظر را روی تصویر اعمال میکند.
ActionBlock<Bitmap>: تصویر نهایی را در دیسک ذخیره میکند.
این بلاکها با استفاده از متد LinkTo به یکدیگر متصل میشوند و یک خط لوله پردازشی را تشکیل میدهند. زیبایی این مدل در این است که به محض اینکه اولین تصویر از مرحله اول عبور میکند، مرحله دوم میتواند پردازش آن را آغاز کند، در حالی که مرحله اول در حال خواندن تصویر بعدی است. این همپوشانی، توان عملیاتی (Throughput) سیستم را به شدت افزایش میدهد.
var executionOptions = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = 4 // اجازه پردازش موازی 4 آیتم
};
// 1. بلاک خواندن فایل
var readFileBlock = new TransformBlock<string, byte[]>(async path =>
{
return await File.ReadAllBytesAsync(path);
}, executionOptions);
// 2. بلاک اعمال فیلتر
var filterBlock = new TransformBlock<byte[], byte[]>(imageBytes =>
{
// منطق اعمال فیلتر در اینجا
return ApplyFilter(imageBytes);
}, executionOptions);
// 3. بلاک ذخیره فایل
var saveFileBlock = new ActionBlock<byte[]>(async imageBytes =>
{
var newPath = GenerateNewPath();
await File.WriteAllBytesAsync(newPath, imageBytes);
}, executionOptions);
// اتصال بلاکها به یکدیگر
var linkOptions = new DataflowLinkOptions { PropagateCompletion = true };
readFileBlock.LinkTo(filterBlock, linkOptions);
filterBlock.LinkTo(saveFileBlock, linkOptions);
الگوی تولیدکننده-مصرفکننده (Producer-Consumer Pattern)
این الگو زمانی کاربرد دارد که یک یا چند وظیفه (تولیدکننده) داده تولید میکنند و یک یا چند وظیفه دیگر (مصرفکننده) آن دادهها را پردازش میکنند. این دو گروه با سرعتهای متفاوتی کار میکنند و یک بافر مشترک بین آنها قرار میگیرد تا این عدم هماهنگی را مدیریت کند.
در TPL Dataflow، بلاک BufferBlock<T> نقش این صف یا بافر مشترک را ایفا میکند. تولیدکننده دادهها را به BufferBlock ارسال (Post) میکند و مصرفکننده دادهها را از آن دریافت (Receive) میکند. این بلاک به صورت پیشفرض thread-safe است و مدیریت پیچیدگیهای دسترسی همزمان به صف را از دوش شما برمیدارد.
این الگو برای سناریوهایی مانند پردازش پیامهای دریافتی از یک صف پیام (مثل RabbitMQ یا Kafka) یا پردازش لاگهای ورودی در لحظه ایدهآل است.
یکی از قدرتمندترین ویژگیهای TPL Dataflow، قابلیت تنظیم دقیق رفتار هر بلاک از طریق ExecutionDataflowBlockOptions است.
MaxDegreeOfParallelism: این گزینه به شما اجازه میدهد مشخص کنید که چند پیام میتوانند به صورت همزمان توسط یک بلاک پردازش شوند. برای مثال، در یک ActionBlock که وظایف CPU-bound انجام میدهد، میتوانید این مقدار را برابر با تعداد هستههای پردازنده تنظیم کنید تا از حداکثر توان سختافزار استفاده شود.
BoundedCapacity: این گزینه حداکثر تعداد پیامهایی که میتوانند در بافر ورودی یک بلاک منتظر بمانند را مشخص میکند. این یک مکانیزم حیاتی برای کنترل فشار معکوس (Back-Pressure) است. اگر یک بلاک مصرفکننده کندتر از بلاک تولیدکننده باشد، بافر آن پر شده و تولیدکننده به صورت خودکار منتظر میماند تا فضا خالی شود. این ویژگی از سرریز شدن حافظه و از دست رفتن دادهها جلوگیری میکند.
CancellationToken: شما میتوانید یک CancellationToken به بلاکها ارسال کنید تا قابلیت لغو عملیات در حال اجرا را به سادگی پیادهسازی کنید.
این سطح از کنترل به شما اجازه میدهد تا سیستمهایی بسازید که نه تنها سریع، بلکه پایدار و مقاوم در برابر بار کاری بالا هستند.
با وجود تمام مزایا، TPL Dataflow راهحل همهچیز نیست. درک زمان مناسب برای استفاده از آن کلیدی است:
موارد استفاده ایدهآل:
خطوط لوله پردازش داده (Data Processing Pipelines): سناریوهایی مانند ETL (Extract, Transform, Load)، پردازش تصویر یا ویدئو، و کامپایل کد که شامل مراحل متوالی و مشخصی هستند.
پردازش جریانی (Stream Processing): پردازش دادهها به محض در دسترس قرار گرفتن، مانند دادههای سنسورها یا رویدادهای بازار بورس.
سناریوهای پیچیده تولیدکننده-مصرفکننده: جایی که نیاز به کنترل دقیق بر بافرینگ و موازیسازی مصرفکنندگان دارید.
سادهسازی کدهای همزمانی پیچیده: هرگاه خود را در حال دستوپنجه نرم کردن با قفلها، سمافورها و دیگر ابزارهای سطح پایین همگامسازی یافتید، TPL Dataflow میتواند یک جایگزین بسیار خواناتر و ایمنتر باشد.
مواردی که شاید انتخاب مناسبی نباشد:
عملیات ساده ناهمزمان: برای یک درخواست وب ساده، استفاده از async/await و HttpClient کافی و سرراستتر است.
موازیسازی یک حلقه ساده: برای موازی کردن یک حلقه for، استفاده از Parallel.ForEach معمولاً سادهتر و کارآمدتر است.
سیستمهای توزیعشده: TPL Dataflow برای پردازش درون یک فرآیند (in-process) طراحی شده است. برای ارتباط بین سرویسهای مختلف، باید از ابزارهایی مانند gRPC، صفهای پیام یا معماریهای مبتنی بر رویداد استفاده کنید.
سناریو: خط لوله تحلیل احساسات نظرات کاربران 📝
فرض کنید سیستمی داریم که نظرات کاربران را از منابع مختلف (مانند فایلهای متنی یا API) دریافت میکند. میخواهیم یک خط لوله پردازشی بسازیم که به صورت موازی و کارآمد کارهای زیر را انجام دهد:
بارگذاری نظرات: خواندن نظرات از فایلهای متنی.
پاکسازی متن: حذف کاراکترهای اضافه و آمادهسازی متن برای تحلیل.
تحلیل احساسات: تشخیص اینکه نظر مثبت، منفی یا خنثی است (در این مثال، به صورت شبیهسازی شده).
دستهبندی و ذخیره: ذخیره نظرات بر اساس احساسات تشخیص داده شده در پایگاه داده یا نمایش در کنسول.
این سناریو برای TPL Dataflow ایدهآل است زیرا شامل مراحل پردازشی متوالی است که میتوانند به صورت موازی روی دادههای مختلف اجرا شوند.
ابتدا، مطمئن شوید که پکیج System.Threading.Tasks.Dataflow را به پروژه خود اضافه کردهاید. میتوانید این کار را با دستور زیر در NuGet Package Manager انجام دهید:
Install-Package System.Threading.Tasks.Dataflow
حالا کد کامل را بررسی میکنیم:
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading.Tasks.Dataflow;
// یک کلاس ساده برای نگهداری اطلاعات نظر
public class UserComment
{
public int Id { get; set; }
public string OriginalText { get; set; }
public string CleanedText { get; set; }
public Sentiment Sentiment { get; set; }
}
public enum Sentiment { Positive, Neutral, Negative }
public class SentimentAnalysisPipeline
{
public static async Task RunAsync()
{
// --- 1. تعریف گزینههای اجرایی برای بلاکها ---
// ما میخواهیم از چندین هسته CPU برای پردازشهای سنگین استفاده کنیم.
var parallelOptions = new ExecutionDataflowBlockOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount // استفاده از تمام هستههای موجود
};
// --- 2. ساخت بلاکهای خط لوله ---
// مرحله اول: ورودی مسیر فایلها را میگیرد و محتوای آنها را میخواند.
// TransformManyBlock مناسب است چون یک مسیر فایل میتواند چندین نظر (خط) داشته باشد.
var loadCommentsBlock = new TransformManyBlock<string, string>(async filePath =>
{
Console.WriteLine($"[Loader] در حال خواندن فایل: {Path.GetFileName(filePath)}");
try
{
return await File.ReadAllLinesAsync(filePath);
}
catch (Exception ex)
{
Console.WriteLine($"خطا در خواندن فایل {filePath}: {ex.Message}");
return Enumerable.Empty<string>(); // در صورت خطا، مجموعه خالی برمیگرداند
}
}, parallelOptions);
// مرحله دوم: متن خام را پاکسازی میکند.
// این یک تبدیل یک-به-یک است، پس از TransformBlock استفاده میکنیم.
int commentIdCounter = 0;
var cleanTextBlock = new TransformBlock<string, UserComment>(text =>
{
Console.WriteLine($"[Cleaner] در حال پاکسازی نظر...");
var cleaned = text.ToLowerInvariant().Trim(); // تبدیل به حروف کوچک و حذف فواصل
// شبیهسازی کمی تاخیر در پردازش
Task.Delay(50).Wait();
return new UserComment
{
Id = Interlocked.Increment(ref commentIdCounter),
OriginalText = text,
CleanedText = cleaned
};
}, parallelOptions);
// مرحله سوم: تحلیل احساسات متن پاکسازی شده.
var analyzeSentimentBlock = new TransformBlock<UserComment, UserComment>(comment =>
{
Console.WriteLine($"[Analyzer] در حال تحلیل نظر ID: {comment.Id}");
// شبیهسازی یک عملیات تحلیل سنگین
Task.Delay(150).Wait();
if (comment.CleanedText.Contains("عالی") || comment.CleanedText.Contains("خوب"))
{
comment.Sentiment = Sentiment.Positive;
}
else if (comment.CleanedText.Contains("بد") || comment.CleanedText.Contains("ضعیف"))
{
comment.Sentiment = Sentiment.Negative;
}
else
{
comment.Sentiment = Sentiment.Neutral;
}
return comment;
}, parallelOptions);
// مرحله چهارم (پایانی): ذخیره یا نمایش نتایج.
// این بلاک خروجی ندارد و فقط یک عمل انجام میدهد، پس ActionBlock بهترین گزینه است.
var storeResultBlock = new ActionBlock<UserComment>(comment =>
{
Console.WriteLine($"✅ [Storage] نتیجه ذخیره شد: (ID: {comment.Id}, Sentiment: {comment.Sentiment}) -> '{comment.OriginalText.Substring(0, Math.Min(20, comment.OriginalText.Length))}'...");
}, new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism = 1 }); // ذخیرهسازی معمولاً بهتر است به صورت ترتیبی انجام شود تا از تداخل جلوگیری شود.
// --- 3. اتصال بلاکها به یکدیگر ---
var linkOptions = new DataflowLinkOptions { PropagateCompletion = true };
loadCommentsBlock.LinkTo(cleanTextBlock, linkOptions);
cleanTextBlock.LinkTo(analyzeSentimentBlock, linkOptions);
analyzeSentimentBlock.LinkTo(storeResultBlock, linkOptions);
// --- 4. ارسال داده به ابتدای خط لوله ---
// فرض میکنیم فایلهای نظرات در یک پوشه قرار دارند
string[] commentFiles = Directory.GetFiles("./comments", "*.txt");
Console.WriteLine($"{commentFiles.Length} فایل نظر برای پردازش یافت شد.");
foreach (var file in commentFiles)
{
await loadCommentsBlock.SendAsync(file);
}
// --- 5. اطلاع به خط لوله که داده دیگری در راه نیست ---
loadCommentsBlock.Complete();
// --- 6. انتظار برای اتمام کار آخرین بلاک ---
// با توجه به PropagateCompletion، تکمیل بلاک اول باعث تکمیل زنجیرهوار بقیه میشود.
await storeResultBlock.Completion;
Console.WriteLine("\n🎉 پردازش تمام نظرات با موفقیت به پایان رسید.");
}
}
یک پوشه به نام comments در کنار فایل اجرایی خود بسازید.
درون این پوشه، چند فایل متنی (مثلاً reviews1.txt, reviews2.txt) با محتوای زیر ایجاد کنید:
reviews1.txt:
این محصول واقعا عالی بود!
کیفیت ساخت خوبی داشت.
بستهبندی میتوانست بهتر باشد.
reviews2.txt:
متاسفانه تجربه خیلی بدی داشتم.
عملکرد دستگاه ضعیف است.
از خریدم راضی هستم، کارم را راه انداخت.
کلاس Program.cs اصلی را برای فراخوانی این خط لوله تغییر دهید:
class Program
{
static async Task Main(string[] args)
{
// آمادهسازی فایلهای نمونه
Directory.CreateDirectory("comments");
await File.WriteAllLinesAsync("comments/reviews1.txt", new[] { "این محصول واقعا عالی بود!", "کیفیت ساخت خوبی داشت.", "بستهبندی میتوانست بهتر باشد." });
await File.WriteAllLinesAsync("comments/reviews2.txt", new[] { "متاسفانه تجربه خیلی بدی داشتم.", "عملکرد دستگاه ضعیف است.", "از خریدم راضی هستم، کارم را راه انداخت." });
await SentimentAnalysisPipeline.RunAsync();
}
}
وقتی برنامه را اجرا میکنید، خواهید دید که پیامهای کنسول به صورت درهم و نامرتب چاپ میشوند. این دقیقاً نشاندهنده اجرای موازی است. بلاک [Loader] ممکن است در حال خواندن فایل دوم باشد، در حالی که بلاک [Cleaner] و [Analyzer] همزمان در حال پردازش نظرات فایل اول هستند. این همپوشانی باعث میشود که CPU بیکار نماند و کل فرآیند بسیار سریعتر از اجرای ترتیبی به پایان برسد.
MaxDegreeOfParallelism: ما به بلاکهای CPU-محور اجازه دادیم تا از تمام هستههای پردازنده استفاده کنند، که باعث افزایش چشمگیر سرعت میشود.
PropagateCompletion: این گزینه حیاتی است. با فعال کردن آن، وقتی کار بلاک اول تمام میشود (loadCommentsBlock.Complete())، یک سیگنال تکمیل به بلاک بعدی ارسال میشود و این زنجیره تا انتها ادامه مییابد. این کار مدیریت پایان عمر خط لوله را بسیار ساده میکند.
انتخاب نوع بلاک مناسب: ما از TransformManyBlock, TransformBlock و ActionBlock بر اساس نیاز هر مرحله استفاده کردیم که باعث خوانایی و کارایی بیشتر کد شد.
ایمنی در برابر خطا: بلوک try-catch در اولین بلاک تضمین میکند که اگر یک فایل خراب باشد، کل خط لوله متوقف نمیشود.
این مثال به وضوح نشان میدهد که چگونه TPL Dataflow به شما امکان میدهد سیستمهای پردازش داده پیچیده، موازی و مقیاسپذیر را با کدی تمیز و قابل مدیریت بسازید.
یادگیری TPL Dataflow یک سرمایهگذاری ارزشمند برای هر توسعهدهنده جدی داتنت است. این کتابخانه به شما اجازه میدهد تا از سطح پایین مدیریت نخها و وظایف فراتر رفته و بر روی معماری جریان داده در برنامه خود تمرکز کنید. با فراهم کردن یک انتزاع سطح بالا و قدرتمند، TPL Dataflow به شما کمک میکند تا کدهای موازی و ناهمزمان را بنویسید که نه تنها سریعتر، بلکه خواناتر، ایمنتر و نگهداریپذیرتر هستند. در دنیایی که کارایی و مقیاسپذیری حرف اول را میزند، تسلط بر این ابزار میتواند شما را به یک مهندس نرمافزار کارآمدتر و توانمندتر تبدیل کند.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.