
پادشاهِ کُدنویسا شو!
اولین و شاید مهمترین گام در طراحی دیتابیس، درک کامل نیازمندیهای کسبوکار یا سیستمی است که دیتابیس برای آن طراحی میشود. این مرحله شامل جمعآوری اطلاعات از ذینفعان، تحلیل فرآیندها و شناسایی دقیق دادههایی است که باید ذخیره و مدیریت شوند.
پس از درک نیازمندیها، فرآیند مدلسازی داده آغاز میشود که معمولاً در سه سطح انجام میپذیرد:
مدل مفهومی (Conceptual Data Model - CDM): این مدل، یک دید سطح بالا از موجودیتهای اصلی، صفات آنها و روابط بین آنها را بدون در نظر گرفتن جزئیات پیادهسازی فنی ارائه میدهد. ابزارهایی مانند نمودارهای ERD (Entity-Relationship Diagram) در این مرحله بسیار کاربرد دارند. موجودیتها (Entities) نمایانگر اشیاء یا مفاهیم دنیای واقعی هستند (مانند دانشجو، درس، سفارش). صفات (Attributes) خصوصیات این موجودیتها را توصیف میکنند (مانند نام دانشجو، کد درس، تاریخ سفارش) و روابط (Relationships) چگونگی ارتباط موجودیتها با یکدیگر را نشان میدهند (مانند یک دانشجو چندین درس را اخذ میکند).
مدل منطقی (Logical Data Model - LDM): در این مرحله، مدل مفهومی به یک ساختار پایگاه دادهای خاص، مانند مدل رابطهای، ترجمه میشود. موجودیتها به جداول، صفات به ستونها و روابط از طریق کلیدهای اصلی و خارجی پیادهسازی میشوند. انتخاب انواع داده مناسب برای هر ستون و تعریف محدودیتهای اولیه نیز در این سطح صورت میگیرد. در این مرحله، هنوز وابستگی به یک سیستم مدیریت پایگاه داده (DBMS) خاص وجود ندارد.
مدل فیزیکی (Physical Data Model - PDM): این مدل، جزئیات پیادهسازی دیتابیس را در یک DBMS خاص (مانند MS SQL Server، Oracle، MySQL) مشخص میکند. مواردی مانند نام دقیق جداول و ستونها، انواع داده خاص DBMS، ایندکسها، پارتیشنبندی و سایر ویژگیهای فیزیکی ذخیرهسازی در این سطح تعریف میشوند.
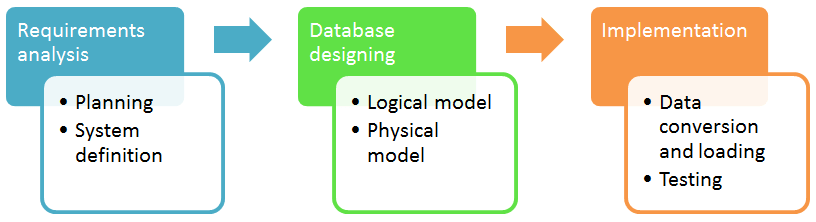
پس از مدلسازی، رعایت چندین اصل کلیدی برای اطمینان از یک طراحی کارآمد و قابل اعتماد ضروری است:
یکپارچگی داده به صحت، سازگاری و قابل اعتماد بودن دادههای ذخیره شده در دیتابیس اشاره دارد. انواع مختلفی از یکپارچگی وجود دارد:
یکپارچگی موجودیت (Entity Integrity): این اصل بیان میکند که هر جدول باید یک کلید اصلی (Primary Key) داشته باشد و مقدار این کلید اصلی برای هیچ رکوردی نمیتواند NULL باشد. کلید اصلی به طور منحصربهفرد هر رکورد را در جدول شناسایی میکند.
-- مثال ایجاد جدول با کلید اصلی در MS SQL Server
CREATE TABLE Students (
StudentID INT PRIMARY KEY, -- کلید اصلی، نمی تواند NULL باشد
FirstName NVARCHAR(50) NOT NULL,
LastName NVARCHAR(50) NOT NULL,
EnrollmentDate DATE
);
یکپارچگی ارجاعی (Referential Integrity): این اصل مربوط به روابط بین جداول است و تضمین میکند که مقادیر یک کلید خارجی (Foreign Key) در یک جدول (جدول فرزند یا ارجاعدهنده) با مقادیر کلید اصلی متناظر در جدول دیگر (جدول والد یا ارجاعشونده) مطابقت داشته باشد یا NULL باشد (اگر ستون کلید خارجی اجازه NULL را بدهد). این اصل از ایجاد رکوردهای "یتیم" جلوگیری میکند.
-- مثال ایجاد جدول با کلید خارجی در MS SQL Server
CREATE TABLE Courses (
CourseID INT PRIMARY KEY,
CourseName NVARCHAR(100) NOT NULL,
Credits INT
);
CREATE TABLE Enrollments (
EnrollmentID INT PRIMARY KEY,
StudentID INT NOT NULL,
CourseID INT NOT NULL,
Grade CHAR(1),
CONSTRAINT FK_Enrollments_Students FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
CONSTRAINT FK_Enrollments_Courses FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
در مثال فوق، FK_Enrollments_Students تضمین میکند که هر StudentID در جدول Enrollments باید یک StudentID معتبر در جدول Students باشد.
یکپارچگی دامنه (Domain Integrity): این اصل اطمینان میدهد که مقادیر وارد شده برای یک ستون خاص، از نوع داده صحیح، فرمت مناسب و در محدوده مجاز باشند. این کار از طریق تعریف انواع داده مناسب (مانند INT, NVARCHAR, DATE, DECIMAL) و استفاده از محدودیتهایی مانند CHECK و NOT NULL انجام میشود.
-- مثال استفاده از محدودیت CHECK در MS SQL Server
ALTER TABLE Courses
ADD CONSTRAINT CK_Credits CHECK (Credits > 0 AND Credits <= 6);
ALTER TABLE Students
ALTER COLUMN FirstName NVARCHAR(50) NOT NULL; -- تضمین می کند نام خالی نباشد
یکپارچگی تعریف شده توسط کاربر (User-Defined Integrity): گاهی اوقات قوانین کسبوکار پیچیدهتر از آن هستند که با محدودیتهای استاندارد پوشش داده شوند. در این موارد میتوان از تریگرها (Triggers)، رویههای ذخیره شده (Stored Procedures) و توابع برای پیادهسازی این قوانین خاص استفاده کرد.
نرمالسازی فرآیندی است برای سازماندهی ستونها و جداول یک دیتابیس رابطهای به منظور کاهش افزونگی داده (Data Redundancy) و بهبود یکپارچگی داده. هدف اصلی، جلوگیری از ناهنجاریهای بهروزرسانی، درج و حذف است. چندین فرم نرمال (Normal Forms - NF) وجود دارد که متداولترین آنها عبارتند از:
فرم نرمال اول (1NF):
مثال نقض 1NF: جدولی که ستونی به نام "تلفنها" دارد و در هر سلول آن چندین شماره تلفن با کاما جدا شده ذخیره شده است. راهحل: ایجاد یک جدول جداگانه برای تلفنها با یک رابطه یک-به-چند با جدول اصلی.
فرم نرمال دوم (2NF):
مثال نقض 2NF: فرض کنید جدولی به نام OrderDetails با کلید اصلی ترکیبی (OrderID, ProductID) داریم و ستونی به نام ProductName نیز در آن وجود دارد. ProductName تنها به ProductID وابسته است، نه به کل ترکیب (OrderID, ProductID). راهحل: انتقال ProductName به جدول Products که کلید اصلی آن ProductID است.
-- قبل از 2NF (فرض کنید OrderID و ProductID کلید اصلی ترکیبی هستند)
-- CREATE TABLE OrderDetails_Pre2NF (
-- OrderID INT,
-- ProductID INT,
-- ProductName NVARCHAR(100), -- وابسته فقط به ProductID
-- Quantity INT,
-- UnitPrice DECIMAL(10, 2),
-- PRIMARY KEY (OrderID, ProductID)
-- );
-- بعد از اعمال 2NF
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName NVARCHAR(100),
UnitPrice DECIMAL(10, 2) -- قیمت واحد نیز معمولا به محصول وابسته است
);
CREATE TABLE OrderDetails (
OrderID INT,
ProductID INT,
Quantity INT,
PRIMARY KEY (OrderID, ProductID),
CONSTRAINT FK_OrderDetails_Orders FOREIGN KEY (OrderID) REFERENCES Orders(OrderID), -- فرض وجود جدول Orders
CONSTRAINT FK_OrderDetails_Products FOREIGN KEY (ProductID) REFERENCES Products(ProductID)
);
فرم نرمال سوم (3NF):
مثال نقض 3NF: در جدول Students، اگر ستونی به نام DepartmentName و ستون دیگری به نام DepartmentHead داشته باشیم و DepartmentHead به DepartmentName وابسته باشد (که خود یک صفت غیرکلیدی است)، این یک وابستگی انتقالی است. راهحل: ایجاد یک جدول جداگانه برای Departments با ستونهای DepartmentName (به عنوان کلید اصلی) و DepartmentHead و سپس در جدول Students از DepartmentName به عنوان کلید خارجی استفاده شود.
-- قبل از 3NF (فرض کنید StudentID کلید اصلی است)
-- CREATE TABLE Students_Pre3NF (
-- StudentID INT PRIMARY KEY,
-- StudentName NVARCHAR(100),
-- DepartmentName NVARCHAR(100),
-- DepartmentHead NVARCHAR(100) -- وابسته به DepartmentName
-- );
-- بعد از اعمال 3NF
CREATE TABLE Departments (
DepartmentName NVARCHAR(100) PRIMARY KEY,
DepartmentHead NVARCHAR(100)
);
CREATE TABLE Students_Post3NF (
StudentID INT PRIMARY KEY,
StudentName NVARCHAR(100),
DepartmentName NVARCHAR(100),
CONSTRAINT FK_Students_Departments FOREIGN KEY (DepartmentName) REFERENCES Departments(DepartmentName)
);
فرم نرمال بویس-کاد (BCNF - Boyce-Codd Normal Form): این فرم، نسخه قویتری از 3NF است. یک جدول در BCNF است اگر و تنها اگر برای هر وابستگی تابعی غیربدیهی X→Y، X یک سوپرکلید (Superkey) باشد. در بسیاری از موارد، رسیدن به 3NF کافی است، اما BCNF افزونگیهای ظریفتری را برطرف میکند.
دنرمالسازی (Denormalization): گاهی اوقات، برای بهبود عملکرد خواندن (Query Performance)، به طور آگاهانه از برخی قوانین نرمالسازی عدول میشود و دادههای افزونه به جداول اضافه میشوند. این کار باید با دقت و پس از تحلیل هزینهها و منافع انجام شود، زیرا میتواند منجر به پیچیدگی در بهروزرسانی دادهها و افزایش ریسک ناسازگاری شود. معمولاً در سیستمهای گزارشگیری و انبارهای داده (Data Warehouses) که حجم خواندن بسیار بالا است، از دنرمالسازی استفاده میشود.
کلیدها ستونها یا مجموعهای از ستونها هستند که برای شناسایی و برقراری ارتباط بین رکوردها استفاده میشوند.
کلید اصلی (Primary Key - PK): به طور منحصربهفرد هر رکورد را در جدول شناسایی میکند. نمیتواند NULL باشد و باید مقادیر یکتا داشته باشد. هر جدول باید یک کلید اصلی داشته باشد.
کلید خارجی (Foreign Key - FK): ستونی (یا مجموعهای از ستونها) در یک جدول است که به کلید اصلی جدول دیگری ارجاع میدهد. برای ایجاد و اعمال روابط بین جداول و حفظ یکپارچگی ارجاعی استفاده میشود.
کلید کاندید (Candidate Key): هر ستون یا مجموعهای از ستونها که بتواند به طور منحصربهفرد رکوردها را شناسایی کند، یک کلید کاندید است. از بین کلیدهای کاندید، یکی به عنوان کلید اصلی انتخاب میشود.
کلید جایگزین (Alternate Key): کلیدهای کاندیدی که به عنوان کلید اصلی انتخاب نشدهاند.
کلید ترکیبی (Composite Key): کلید اصلی یا کاندیدی که از بیش از یک ستون تشکیل شده است.
کلید جانشین (Surrogate Key): یک کلید مصنوعی (معمولاً یک عدد صحیح با افزایش خودکار مانند IDENTITY در MS SQL Server یا SERIAL در PostgreSQL) که هیچ معنای کسبوکاری ندارد و صرفاً برای شناسایی منحصربهفرد رکوردها استفاده میشود. استفاده از کلیدهای جانشین اغلب به دلیل سادگی و پایداری (عدم تغییر با تغییر دادههای کسبوکاری) توصیه میشود.
-- استفاده از کلید جانشین (IDENTITY) در MS SQL Server
CREATE TABLE Employees (
EmployeeID INT IDENTITY(1,1) PRIMARY KEY, -- کلید جانشین، شروع از 1 با گام 1
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
NationalCode CHAR(10) UNIQUE NOT NULL -- یک کلید کاندید طبیعی
);
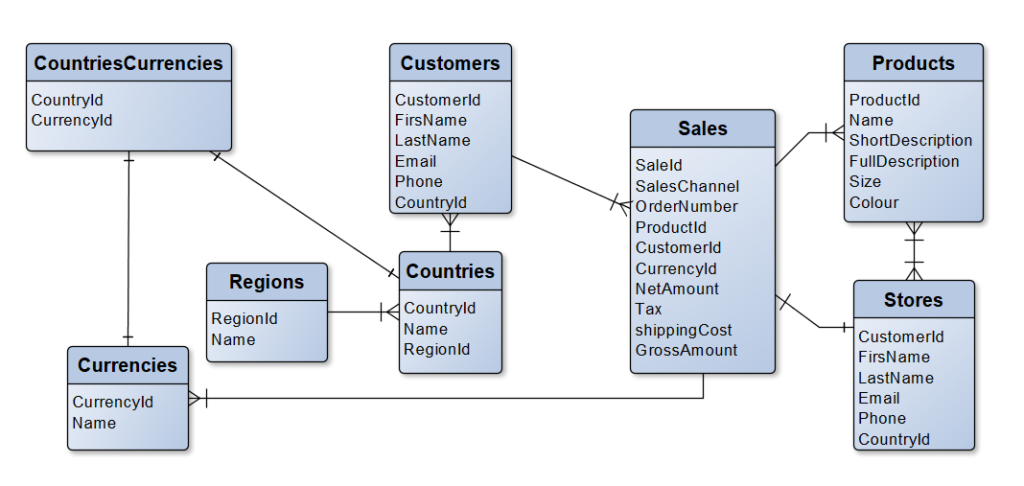
روابط نشاندهنده چگونگی ارتباط موجودیتها (جداول) با یکدیگر هستند:
یک-به-یک (One-to-One): هر رکورد در جدول A با حداکثر یک رکورد در جدول B مرتبط است و بالعکس. این نوع رابطه کمتر رایج است و گاهی نشاندهنده این است که دو جدول میتوانند ادغام شوند، مگر اینکه دلایل خاصی برای جداسازی (مانند امنیت یا اختیاری بودن بخشی از دادهها) وجود داشته باشد. پیادهسازی معمولاً با قرار دادن کلید اصلی یک جدول به عنوان کلید خارجی (و منحصربهفرد) در جدول دیگر انجام میشود.
یک-به-چند (One-to-Many): هر رکورد در جدول A (والد) میتواند با صفر، یک یا چند رکورد در جدول B (فرزند) مرتبط باشد، اما هر رکورد در جدول B تنها با یک رکورد در جدول A مرتبط است. این رایجترین نوع رابطه است. (مثال: یک Customer میتواند چندین Order داشته باشد).
چند-به-چند (Many-to-Many): هر رکورد در جدول A میتواند با صفر، یک یا چند رکورد در جدول B مرتبط باشد و بالعکس. این نوع رابطه به طور مستقیم در مدل رابطهای قابل پیادهسازی نیست و نیاز به یک جدول اتصال (Junction Table یا Associative Table) دارد. جدول اتصال شامل کلیدهای خارجی از هر دو جدول اصلی است و کلید اصلی آن معمولاً ترکیبی از این دو کلید خارجی است.
-- پیاده سازی رابطه چند-به-چند بین Students و Courses
-- جدول Students و Courses قبلا تعریف شده اند
CREATE TABLE StudentCourses (
StudentID INT,
CourseID INT,
EnrollmentDate DATE,
PRIMARY KEY (StudentID, CourseID), -- کلید اصلی ترکیبی
CONSTRAINT FK_StudentCourses_Students FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
CONSTRAINT FK_StudentCourses_Courses FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
در این مثال، StudentCourses جدول اتصال است که رابطه چند-به-چند بین دانشجویان و دروس را پیادهسازی میکند.
انتخاب نوع داده مناسب برای هر ستون بسیار مهم است. این انتخاب بر فضای ذخیرهسازی، عملکرد و یکپارچگی دادهها تأثیر میگذارد.
ایندکسها ساختارهای دادهای ویژهای هستند که سرعت بازیابی رکوردها را از جداول دیتابیس افزایش میدهند. آنها مانند فهرست یک کتاب عمل میکنند و به DBMS اجازه میدهند تا رکوردهای مورد نظر را بدون اسکن کامل جدول پیدا کند.
ملاحظات ایندکسگذاری:
-- ایجاد ایندکس غیرکلاستر شده در MS SQL Server
CREATE NONCLUSTERED INDEX IX_Students_LastName
ON Students (LastName);
-- ایجاد یک ایندکس ترکیبی
CREATE NONCLUSTERED INDEX IX_Enrollments_Course_Student
ON Enrollments (CourseID, StudentID);
محدودیتها (Constraints): علاوه بر کلیدهای اصلی و خارجی، از محدودیتهای دیگری مانند UNIQUE (تضمین یکتایی مقادیر در یک ستون غیر از کلید اصلی)، CHECK (اعمال یک شرط بر روی مقادیر ستون) و DEFAULT (تعیین یک مقدار پیشفرض برای ستون در صورت عدم ارائه مقدار هنگام درج) برای تقویت یکپارچگی داده استفاده کنید.
-- مثال استفاده از محدودیت UNIQUE و DEFAULT در MS SQL Server
ALTER TABLE Employees
ADD CONSTRAINT UQ_Employees_NationalCode UNIQUE (NationalCode);
ALTER TABLE Students
ADD CONSTRAINT DF_Students_EnrollmentDate DEFAULT GETDATE() FOR EnrollmentDate;
نماها (Views): نماها، جداول مجازی هستند که بر اساس نتیجه یک کوئری ذخیره شده تعریف میشوند. از نماها میتوان برای سادهسازی کوئریهای پیچیده، محدود کردن دسترسی به دادهها (نمایش تنها ستونها یا ردیفهای خاص) و ارائه یک لایه انتزاعی بر روی ساختار جداول پایه استفاده کرد.
-- ایجاد یک نما در MS SQL Server
CREATE VIEW Vw_StudentCourseDetails
AS
SELECT
s.FirstName,
s.LastName,
c.CourseName,
e.Grade
FROM Students s
JOIN Enrollments e ON s.StudentID = e.StudentID
JOIN Courses c ON e.CourseID = c.CourseID;
-- استفاده از نما
SELECT * FROM Vw_StudentCourseDetails WHERE LastName = N'احمدی';
رویههای ذخیره شده (Stored Procedures) و توابع (Functions):
نامگذاری استاندارد (Naming Conventions): از یک استاندارد نامگذاری یکنواخت و معنادار برای جداول، ستونها، ایندکسها و سایر اشیاء دیتابیس استفاده کنید. این کار خوانایی و نگهداری دیتابیس را به شدت بهبود میبخشد. (مثلاً استفاده از PascalCase برای نام جداول و ستونها مانند StudentCourses، یا snake_case مانند student_courses).
مستندسازی: طراحی دیتابیس خود را، از جمله مدل داده، روابط، انواع داده، محدودیتها و قوانین کسبوکار پیادهسازی شده را به طور کامل مستند کنید.
نرمالسازی بیش از حد (Over-normalization): منجر به تعداد زیادی جدول کوچک و نیاز به JOIN های متعدد میشود که میتواند عملکرد را کاهش دهد.
طراحی دیتابیس یک هنر و علم است که نیازمند درک عمیق از نیازمندیهای کسبوکار، اصول نظری پایگاه داده و ویژگیهای عملی سیستم مدیریت پایگاه داده مورد استفاده است. با رعایت اصول اساسی مانند مدلسازی دقیق داده، اعمال یکپارچگی داده، نرمالسازی مناسب، انتخاب هوشمندانه کلیدها و انواع داده، و استفاده بهینه از ایندکسها، میتوان دیتابیسهایی کارآمد، قابل اعتماد و قابل نگهداری ایجاد کرد که ستون فقرات سیستمهای اطلاعاتی موفق را تشکیل میدهند. فرآیند طراحی دیتابیس یک فرآیند تکرارشونده است و با تکامل نیازمندیها، ممکن است نیاز به بازنگری و بهبود داشته باشد.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.