
پادشاهِ کُدنویسا شو!
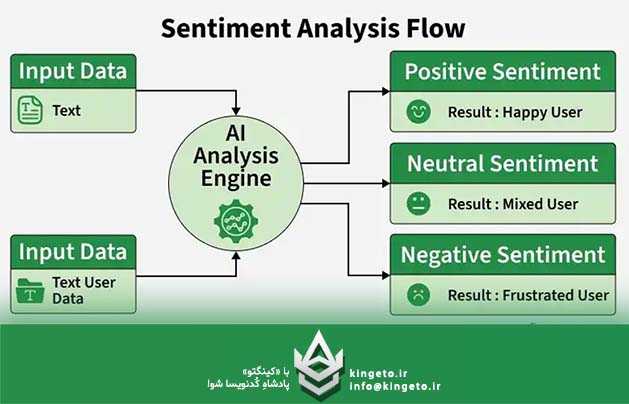
پیادهسازی این فرآیند برای زبان فارسی، به دلیل ویژگیهای ساختاری و خطی آن، چالشهای منحصربهفردی دارد:
ریختشناسی (Morphology) پیچیده و پیشوندها/پسوندهای متعدد
عدم وجود استاندارد واحد در استفاده از نیمفاصله (مانند «می شود» در مقابل «میشود»)
تعدد واژگان غیررسمی، عامیانه و شکستهنویسیهای رایج در شبکههای اجتماعی
وجود ابهام و کنایه (Sarcasm) در ساختار جملات فارسی
در اکوسیستم مایکروسافت، توسعهدهندگان به لطف فریمورک قدرتمند ML.NET میتوانند بدون نیاز به مهاجرت به پایتون، مدلهای یادگیری ماشین پیشرفته را در بستر .NET 8/9 پیادهسازی، آموزش و مستقر کنند. این مقاله به صورت جامع و معماریمحور، روند ساخت یک خط لوله (Pipeline) کامل برای تحلیل احساسات متون فارسی را با استفاده از C# و ML.NET بررسی میکند.
پیشپردازش مهمترین گام در NLP زبان فارسی است. دادههای خام متنی معمولاً حاوی نویزهایی هستند که دقت مدل را به شدت کاهش میدهند.
نرمالسازی (Normalization)
اولین قدم، یکدستسازی نویسهها است. برای مثال، حرف «ی» در زبان عربی (ي) با فارسی متفاوت است و کدهای اسکی (ASCII) متفاوتی دارند. همچنین اصلاح نیمفاصلهها در این بخش انجام میشود.
توکنسازی (Tokenization) و حذف کلمات توقف (Stop Words)
متن باید به کلمات مجزا (Tokens) شکسته شود. سپس کلماتی مانند «از»، «به»، «که» و «در» که بار معنایی خاصی برای تشخیص احساسات ندارند، حذف میشوند.
برای زبان فارسی، ابزارهایی مانند Hazm یا Parsivar گزینههای عالی هستند، اما در محیط native .NET، میتوان از پورتهای داتنتی آنها (مانند Hazm.NET) یا کتابخانههای سفارشی مبتنی بر Regex استفاده کرد.
public class PersianTextNormalizer
{
public static string Normalize(string text)
{
if (string.IsNullOrWhiteSpace(text)) return string.Empty;
// تبدیل ی و ک عربی به فارسی
text = text.Replace("ي", "ی").Replace("ك", "ک");
// تنظیم نیمفاصلهها (مثال ساده)
text = System.Text.RegularExpressions.Regex.Replace(text, @"\sمی\s", " می");
// حذف نشانههای نگارشی و اعداد
text = System.Text.RegularExpressions.Regex.Replace(text, @"[^\w\s]", "");
return text.Trim();
}
}
در ML.NET، دادهها از طریق اینترفیس IDataView مدیریت میشوند. برای آموزش مدل تحلیل احساسات (دوبخشی یا Binary Classification)، به دو کلاس اصلی برای تعریف ورودی و خروجی نیاز داریم.
public class SentimentData
{
[LoadColumn(0)]
public string Text { get; set; }
[LoadColumn(1), ColumnName("Label")]
public bool Sentiment { get; set; } // True: مثبت، False: منفی
}
public class SentimentPrediction : SentimentData
{
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
public float Probability { get; set; }
public float Score { get; set; }
}
کامپیوترها زبان متنی را درک نمیکنند؛ بنابراین متن باید به بردارهای عددی تبدیل شود. در ML.NET، ابزار FeaturizeText این وظیفه را بر عهده دارد. این متد به صورت خودکار مراحل زیر را اعمال میکند:
Case-changing (که برای فارسی کاربردی ندارد اما خطا ایجاد نمیکند).
Tokenization بر اساس فضاهای خالی.
N-gram Extraction (استخراج ترکیبات دو یا چند کلمهای مانند «خیلی خوب»).
TF-IDF (Term Frequency-Inverse Document Frequency) برای وزندهی به اهمیت کلمات در کل مجموعه داده.
var mlContext = new MLContext(seed: 42);
// تعریف خط لوله تبدیل متن به ویژگیهای عددی
var dataProcessPipeline = mlContext.Transforms.Text.FeaturizeText(
outputColumnName: "Features",
inputColumnName: nameof(SentimentData.Text)
);
پس از تبدیل متن به ویژگی (Features)، باید یک الگوریتم دستهبندی مناسب انتخاب کنیم. برای تحلیل احساسات، الگوریتمهای زیر در ML.NET کارایی بالایی دارند:
SdcaLogisticRegression (Stochastic Dual Coordinate Ascent)
LbfgsLogisticRegression
GamBinary (Generalized Additive Models)
در این سناریو، از الگوریتم قدرتمند SdcaLogisticRegression استفاده میکنیم:
// ترکیب فرآیند پردازش متن با الگوریتم یادگیری ماشین
var trainer = mlContext.BinaryClassification.Trainers.SdcaLogisticRegression(
labelColumnName: "Label",
featureColumnName: "Features"
);
var trainingPipeline = dataProcessPipeline.Append(trainer);
// بارگذاری دادهها از فایل CSV یا دیتابیس (مانند SQL Server)
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<SentimentData>(
path: "persian_sentiment_dataset.csv",
hasHeader: true,
separatorChar: ','
);
// آموزش مدل
Console.WriteLine("در حال آموزش مدل... لطفا شکیبا باشید.");
var trainedModel = trainingPipeline.Fit(trainingDataView);
یک مهندس ارشد نرمافزار هرگز بدون ارزیابی دقیق، مدلی را وارد محیط عملیاتی نمیکند. برای ارزیابی مدل تحلیل احساسات، دادهها را به دو بخش تست (Test) و آموزش (Train) تقسیم کرده و معیارهای زیر را بررسی میکنیم:
Accuracy (دقت کل): نسبت پیشبینیهای درست به کل دادهها.
AUC (Area Under ROC Curve): نشاندهنده توانایی مدل در تفکیک کلاسهای مثبت و منفی.
F1-Score: تعادل بین دو معیار Precision و Recall (بسیار حیاتی برای مجموعهدادههای نامتوازن).
// ارزیابی مدل با دادههای تست
var predictions = trainedModel.Transform(testDataView);
var metrics = mlContext.BinaryClassification.Evaluate(
data: predictions,
labelColumnName: "Label",
scoreColumnName: "Score"
);
Console.WriteLine($"Accuracy: {metrics.Accuracy:P2}");
Console.WriteLine($"AUC: {metrics.AreaUnderRocCurve:P2}");
Console.WriteLine($"F1-Score: {metrics.F1Score:P2}");
پس از تایید کیفیت مدل، باید آن را به صورت یک فایل zip ذخیره کرده و در یک وبسرویس با کارایی بالا (High-Performance ASP.NET Core Web API) مستقر کنیم. برای مدیریت Thread-Safe بودن مدل و جلوگیری از ایجاد گلوگاه در درخواستهای همزمان، استفاده از اینترفیس PredictionEnginePool الزامی است.
mlContext.Model.Save(trainedModel, trainingDataView.Schema, "PersianSentimentModel.zip");
builder.Services.AddPredictionEnginePool<SentimentData, SentimentPrediction>()
.FromFile("PersianSentimentModel.zip");
[ApiController]
[Route("api/[controller]")]
public class SentimentController : ControllerBase
{
private readonly PredictionEnginePool<SentimentData, SentimentPrediction> _predictionEnginePool;
public SentimentController(PredictionEnginePool<SentimentData, SentimentPrediction> predictionEnginePool)
{
_predictionEnginePool = predictionEnginePool;
}
[HttpPost("analyze")]
public IActionResult Analyze([FromBody] string text)
{
if (string.IsNullOrWhiteSpace(text)) return BadRequest("متن نمیتواند خالی باشد.");
// پیشپردازش متن ورودی
var normalizedText = PersianTextNormalizer.Normalize(text);
var input = new SentimentData { Text = normalizedText };
var prediction = _predictionEnginePool.Predict(input);
return Ok(new
{
OriginalText = text,
NormalizedText = normalizedText,
IsPositive = prediction.Prediction,
Confidence = prediction.Probability,
Score = prediction.Score
});
}
}
اگرچه الگوریتمهای سنتی ماشین لرنینگ مانند SDCA سریع و کمهزینه هستند، اما در درک کنایهها و ساختارهای عمیق زبان فارسی مانند مدلهای ترنسفورمر (Transformers) دقیق عمل نمیکنند.
برای دستیابی به بالاترین دقت ممکن در متون فارسی، میتوان از مدل ParsBERT (یک مدل BERT بومیسازی شده برای زبان فارسی) استفاده کرد. با ظهور نسخه جدید .NET 9 و توسعه کتابخانههایی چون Microsoft.ML.TorchSharp یا بسترهای ONNX، شما میتوانید مدلهای ParsBERT را که در پایتون آموزش دیدهاند، به فرمت ONNX تبدیل کرده و مستقیماً با بالاترین سرعت و به صورت کامپایلشده درون خط لوله C# اجرا کنید.
// نمونهای از نحوه افزودن یک مدل تخصصی ONNX به خط لوله ML.NET
var onnxEstimator = mlContext.Transforms.ApplyOnnxModel(
modelFile: "parsbert_model.onnx",
outputColumnNames: new[] { "output_layer" },
inputColumnNames: new[] { "input_ids", "attention_mask" }
);
تحلیل احساسات متون فارسی با .NET دیگر یک رویای دور از دسترس نیست. فریمورک ML.NET به توسعهدهندگان سیشارپ این امکان را میدهد که از معماریهای تمیز (Clean Architecture) و الگوهای طراحی استاندارد استفاده کرده و بدون دغدغههای مربوط به یکپارچهسازی زبانهای مختلف (مانند فراخوانی اسکریپتهای پایتون در داتنت)، سیستمهای هوش مصنوعی با کارایی بالا بسازند. کلید موفقیت در این مسیر، پیشپردازش دقیق و بومیسازیشده زبان فارسی و انتخاب الگوریتم یا مدل متناسب با حجم داده و نیاز کسبوکار است.















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.