
پادشاهِ کُدنویسا شو!
نگاه کلی:
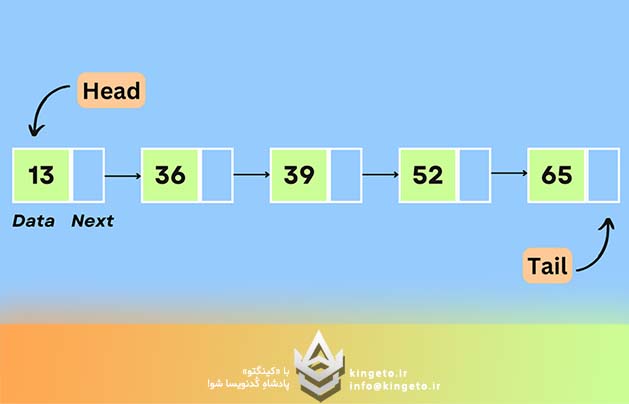
لیست پیوندی دنبالهای از گرهها (Nodes) است که هر گره شامل دو بخش است:
آخرین گره به جای اشاره به گره بعدی، به مقدار تهی (null) اشاره میکند که نشاندهنده پایان لیست است.
یک لیست پیوندی ساده از اعداد:
[3] → [8] → [1] → [4] → null
نگاه دات نتی:
یک Linked List، یک ساختار داده خطی است؛ اما برخلاف آرایهها، عناصر آن در خانههای پشت سر هم و متوالی حافظه (Contiguous Memory) قرار نمیگیرند. در عوض، هر عنصر یک شیء مستقل به نام گره (Node) است.
هر گره از دو بخش اصلی تشکیل شده است:
تخصیص حافظه در لیست پیوندی به صورت پویا (Dynamic Heap Allocation) انجام میشود. یعنی هر زمان که گره جدیدی ایجاد میشود، سیستمعامل یا runtime داتنت (CLR) بخشی از حافظه Heap را به آن اختصاص میدهد و گره قبلی صرفاً به این آدرس جدید اشاره میکند.
انواع لیست پیوندی:
برای درک اینکه چرا و کجا باید از لیست پیوندی استفاده کنیم، باید رفتار این دو ساختار داده را در بخشهای مختلف مدیریت حافظه و پیچیدگی زمانی (Time Complexity) مقایسه کنیم.
الف) مدیریت حافظه (Memory Management)
Array: هنگام تعریف آرایه، یک بلوک متوالی و یکپارچه از حافظه RAM رزرو میشود. این امر باعث میشود آرایه از Locality of Reference (محل ارجاع محلی) فوقالعادهای بهرهمند شود؛ زیرا پردازنده (CPU) میتواند کل آرایه یا بخش زیادی از آن را وارد حافظه Cache کند که سرعت دسترسی را بهشدت بالا میبرد. اما مشکل اینجاست که اندازه آرایه ثابت (Fixed Size) است.
Linked List: گرهها در سراسر حافظه Heap پخش شدهاند. این یعنی فاقد Cache Locality هستند و برای خواندن هر گره، CPU باید مرتباً به حافظه اصلی مراجعه کند (Cache Miss). اما مزیت بزرگ آن، عدم نیاز به بلوک متوالی است؛ شما میتوانید تا جایی که RAM ظرفیت دارد، گره جدید اضافه کنید بدون اینکه نگران پر شدن فضای یکپارچه باشید.
ب) پیچیدگی زمانی عملیات (Big O Complexity)
| عملیات (Operation) | Array / List | Linked List (Doubly) | توضیح تفاوتی |
|---|---|---|---|
| دسترسی با اندیس (Indexing) | O(1) | O(n) | در آرایه با فرمول ریاضی مستقیماً به آدرس میرسیم. در لیست باید از ابتدا تکتک گرهها را پیمایش کنیم. |
| درج/حذف در ابتدا (Insert/Delete at Start) | O(n) | O(1) | در آرایه باید تمام عناصر به سمت راست شیفت پیدا کنند. در لیست پیوندی فقط جای دو ارجاع (Pointer) عوض میشود. |
| درج/حذف در انتها (Insert/Delete at End) | O(1) amortized | O(1) | در آرایه اگر ظرفیت پر باشد، نیاز به Resize و کپی کل آرایه است. در لیست با داشتن ارجاع به گره آخر (Tail)، عملیات آنی است. |
| درج/حذف در میانه (Insert/Delete in Middle) | O(n) | O(1) (با داشتن نود) | در لیست پیوندی، اگر به گره مورد نظر ارجاع داشته باشیم، حذف یا اضافه کردن بدون هیچ شیفت دادنی و در O(1) انجام میشود. |
در داتنت، مایکروسافت کلاس کلاسیک
باید توجه داشت که کلاس محبوب List در سیشارپ، برخلاف نامش، یک لیست پیوندی نیست! بلکه در پشت صحنه یک آرایه پویا (Dynamic Array) است که به محض پر شدن، آرایهای با دو برابر حجم قبلی ساخته و دادهها را کپی میکند.
بیا یک نمونه کد تمیز از نحوه کار با
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// ایجاد یک لیست پیوندی از رشتهها
LinkedList priorityTasks = new LinkedList();
// ۱. اضافه کردن به انتها - O(1)
LinkedListNode node2 = priorityTasks.AddLast("Task 2: Process Data");
priorityTasks.AddLast("Task 3: Write Logs");
// ۲. اضافه کردن به ابتدای لیست - O(1)
LinkedListNode firstNode = priorityTasks.AddFirst("Task 1: Validate Request");
// ۳. درج یک گره در میانه لیست (بعد از یک گره مشخص) - O(1)
priorityTasks.AddAfter(node2, "Task 2.5: Mid-Process Check");
// پیمایش لیست پیوندی از ابتدا به انتها
Console.WriteLine("Forward Traversal:");
foreach (var task in priorityTasks)
{
Console.WriteLine($" -> {task}");
}
// ۴. حذف یک گره مشخص بدون شیفت دادن حافظه - O(1)
priorityTasks.Remove(node2);
// پیمایش معکوس با استفاده از ویژگی دوطرفه بودن (Doubly Linked)
Console.WriteLine("\nBackward Traversal:");
LinkedListNode current = priorityTasks.Last;
while (current != null)
{
Console.WriteLine($" <- {current.Value}");
current = current.Previous; // حرکت به سمت عقب
}
}
}
شاید بپرسی: «وقتی List با مزیای Cache Locality انقدر سریع است، چرا باید در یک پروژه تجاری واقعی از LinkedList استفاده کنم؟»
پاسخ در سناریوهایی نهفته است که در آنها حذف و درجهای مداوم و پرتعداد در ابتدا، انتها یا میانه ساختار داده رخ میدهد و ما نمیتوانیم هزینه سنگین شیفت دادن آرایه (O(n)) یا بازآرایی حافظه (Garbage Collection overhead به دلیل کپی آرایههای بزرگ) را بپذیریم.
پروژه واقعی: طراحی یک مکانیزم In-Memory Cache با استراتژی LRU (Least Recently Used)
در سیستمهای بزرگ (مانند توزیعکنندههای محتوا، سیستمهای مالی یا وبسایتهای پربازدید)، ما دادهها را در حافظه منبع (RAM) کش میکنیم تا سرعت پاسخدهی بالا برود. اما حافظه RAM محدود است. وقتی ظرفیت کش پر میشود، باید آیتمی که از همه دیرتر مورد استفاده قرار گرفته است (Least Recently Used) را حذف کنیم تا جا برای داده جدید باز شود.
چرا آرایه یا List برای LRU فاجعه است؟
برای پیادهسازی LRU، هر زمان که کاربر به یک داده دسترسی پیدا میکند، آن داده باید به «ابتدای لیست» منتقل شود (چون به تازگی استفاده شده). اگر از آرایه استفاده کنیم، هر بار دسترسی به یک آیتم به معنای شیفت دادن هزاران آیتم دیگر در حافظه است که CPU را کلاستر میکند.
راهکار معماری: ترکیب Dictionary و LinkedList
برای ساخت یک کش LRU فوقسریع با پیچیدگی زمانی O(1) برای تمام عملیاتها، دو ساختار را ترکیب میکنیم:
یک Dictionary> برای دسترسی آنی (O(1)) به آدرس گرهها در حافظه.
یک LinkedList برای نگهداری ترتیب استفاده از آیتمها. به این صورت که آیتمهای جدید یا بهتازگی استفاده شده همیشه به ابتدا (Head) میآیند و آیتمهای قدیمی در انتها (Tail) رسوب میکنند تا حذف شوند.
در ادامه یک پیادهسازی Thread-Safe، بهینه و واقعی از این مکانیزم را با هم مرور میکنیم:
using System;
using System.Collections.Generic;
public class LruCache
{
private readonly int _capacity;
private readonly Dictionary> _cacheMap;
private readonly LinkedList _cacheList;
private readonly object _lock = new object(); // برای سناریوهای Multi-threading
// ساختار داخلی برای ذخیره همزمان کلید و مقدار در نود
private class CacheItem
{
public TKey Key { get; }
public TValue Value { get; set; }
public CacheItem(TKey key, TValue value)
{
Key = key;
Value = value;
}
}
public LruCache(int capacity)
{
if (capacity <= 0) throw new ArgumentException("Capacity must be greater than zero.");
_capacity = capacity;
_cacheMap = new Dictionary>(capacity);
_cacheList = new LinkedList();
}
// دریافت داده از کش - O(1)
public bool TryGet(TKey key, out TValue value)
{
lock (_lock)
{
if (!_cacheMap.TryGetValue(key, out LinkedListNode node))
{
value = default;
return false;
}
// گره پیدا شد؛ پس به تازگی استفاده شده. انتقال به ابتدای لیست پیوندی (O(1))
value = node.Value.Value;
_cacheList.Remove(node);
_cacheList.AddFirst(node);
return true;
}
}
// اضافه کردن یا بهروزرسانی داده در کش - O(1)
public void Set(TKey key, TValue value)
{
lock (_lock)
{
if (_cacheMap.TryGetValue(key, out LinkedListNode node))
{
// آیتم از قبل وجود دارد؛ مقدار را بهروز کن و به اول لیست ببر
node.Value.Value = value;
_cacheList.Remove(node);
_cacheList.AddFirst(node);
}
else
{
// اگر ظرفیت پر است، آیتم قدیمی را از انتها حذف کن (O(1))
if (_cacheMap.Count >= _capacity)
{
RemoveLeastRecentlyUsed();
}
// ایجاد گره جدید و افزودن به ابتدای لیست
var cacheItem = new CacheItem(key, value);
var newNode = _cacheList.AddFirst(cacheItem);
_cacheMap.Add(key, newNode);
}
}
}
// حذف پیرترین آیتم از انتهای لیست پیوندی - O(1)
private void RemoveLeastRecentlyUsed()
{
LinkedListNode oldestNode = _cacheList.Last;
if (oldestNode != null)
{
_cacheMap.Remove(oldestNode.Value.Key);
_cacheList.RemoveLast();
}
}
public int Count
{
get { lock (_lock) return _cacheMap.Count; }
}
}
تحلیل عملکرد کد بالا در پروژه واقعی:
در این سیستم کش، وقتی متد Set یا TryGet صدا زده میشود، به کمک دیکشنری نودِ مورد نظر را در زمان O(1) پیدا میکنیم. سپس با متدهای نیتیو LinkedList داتنت، آن نود را بدون اینکه نیاز باشد هیچ عنصری در حافظه جابهجا یا شیفت داده شود، از جای خود خارج کرده و به ابتدای لیست میآوریم (AddFirst). این یعنی پیادهسازی یک قابلیت بسیار پیشرفته با کمترین هزینه سربار پردازنده (CPU Overhead).
به عنوان یک قانون کلی در طراحی معماری نرمافزار، این چکلیست را همیشه همراه داشته باشید:
✅ چراغ سبز برای انتخاب Linked List:
تعداد نامشخص دادهها: زمانی که اصلاً نمیدانید سیستم قرار است با چه حجمی از داده کار کند و تمایلی به تحمیل هزینههای سنگینِ بازآرایی آرایههای پویا (List) ندارید.
عملیاتهای مداوم در ابتدا یا میانه لیست: مانند پیادهسازی صفهای اولویتدار (Priority Queues)، سیستمهای Undo/Redo در نرمافزارهای گرافیکی یا متنی، و مدیریت بافرهای مدور (Circular Buffers).
محدودیت در داشتن بلوکهای حافظه متوالی: اگر حافظه سیستم تکهتکه (Fragmented) شده باشد، آرایههای بزرگ قابل تخصیص نیستند، اما لیست پیوندی میتواند از تکههای خرد شده حافظه بهخوبی استفاده کند.
❌ چراغ قرمز (ترجیح دادن Array یا List):
نیاز به دسترسی تصادفی فراوان (Random Access): اگر سیستم شما مدام از طریق ایندکس (مثلاً data[500]) به دادهها دسترسی پیدا میکند، لیست پیوندی به دلیل نیاز به پیمایش خطی (O(n)) پروژه شما را کند خواهد کرد.
محدودیت شدید در مصرف RAM: هر گره در یک لیست پیوندی دوطرفه در سیشارپ، علاوه بر خودِ داده، نیاز به ذخیره دو ارجاع (Pointer) ۶۴ بیتی دارد. این یعنی سربار حافظه (Memory Overhead) برای دادههای کوچک (مثل int یا byte) بسیار بالا خواهد بود.
اهمیت بالای سرعت در پیمایشهای متوالی ساده: به دلیل عدم پشتیبانی از Cache Locality، در یک حلقه foreach ساده، آرایهها همیشه لیستهای پیوندی را شکست میدهند.
در یک لیست پیوندی معمولی، گره آخر به null اشاره میکند. اما اگر به دلیل خطای برنامهنویسی یا طراحی خاص، یک گره به یکی از گرههای قبلی اشاره کند، یک چرخه (حلقه) ایجاد میشود.مثال:
[1] → [2] → [3] → [4] → [2]
در اینجا گره چهارم دوباره به گره دوم اشاره میکند. اگر از ابتدا شروع به پیمایش کنیم، هرگز به null نمیرسیم و در حلقه بینهایت میافتیم.
مشکل: پیدا کردن گره شروع چرخه
گره شروع چرخه اولین گرهای است که هنگام ورود به چرخه از سمت سر لیست با آن برخورد میکنیم. در مثال بالا، گره شروع چرخه، گره با مقدار 2 است (چون از 1 به 2 میرویم و سپس 2 → 3 → 4 → دوباره 2).
چرا یافتن گره شروع چرخه مهم است؟
الگوریتم فلوید (Floyd’s Cycle Detection)
معروفترین روش برای تشخیص چرخه و یافتن گره شروع، الگوریتم گاو و خرگوش (Tortoise and Hare) یا الگوریتم فلوید است. این الگوریتم از دو اشارهگر استفاده میکند و حافظه اضافی مصرف نمیکند (O(1)).
مرحله 1: تشخیص وجود چرخه
مرحله 2: یافتن گره شروع چرخه
اثبات ریاضی ساده
فرض کنیم:
زمانی که slow و fast به هم میرسند:
از آنجا که fast دو برابر slow حرکت میکند:
2(m + k) = m + k + nL
⇒ m + k = nL
⇒ m = nL - k
یعنی فاصله از سر تا گره شروع (m) برابر است با فاصله از محل برخورد تا گره شروع در ادامه چرخه. به همین دلیل وقتی یکی از سر و دیگری از محل برخورد شروع به حرکت کنند، دقیقاً در گره شروع به هم میرسند.
using System;
class Node
{
public int Value;
public Node Next;
public Node(int val) { Value = val; Next = null; }
}
class CycleDetector
{
public static Node FindCycleStart(Node head)
{
if (head == null) return null;
// مرحله 1: تشخیص چرخه
Node slow = head;
Node fast = head;
bool hasCycle = false;
while (fast != null && fast.Next != null)
{
slow = slow.Next;
fast = fast.Next.Next;
if (slow == fast)
{
hasCycle = true;
break;
}
}
if (!hasCycle) return null;
// مرحله 2: پیدا کردن گره شروع
slow = head;
while (slow != fast)
{
slow = slow.Next;
fast = fast.Next;
}
return slow;
}
}
class Program
{
static void Main()
{
// ساخت لیست دارای چرخه: 1 -> 2 -> 3 -> 4 -> 5 -> 3
Node n1 = new Node(1);
Node n2 = new Node(2);
Node n3 = new Node(3);
Node n4 = new Node(4);
Node n5 = new Node(5);
n1.Next = n2;
n2.Next = n3;
n3.Next = n4;
n4.Next = n5;
n5.Next = n3; // ایجاد چرخه به گره 3
Node start = CycleDetector.FindCycleStart(n1);
if (start != null)
Console.WriteLine("چرخه از گره با مقدار {0} شروع میشود", start.Value);
else
Console.WriteLine("چرخهای وجود ندارد.");
}
}
خروجی:
چرخه از گره با مقدار 3 شروع میشود
تحلیل پیچیدگی
مفهوم Linked List یکی از بنیادیترین مفاهیم ساختار داده است که در سطح فریمورکها و هسته سیستمعاملها کاربردهای حیاتی دارد. در سیشارپ، درک عمیق تفاوت رفتار LinkedList و List در حافظه Heap، مرز میان یک کدنویس معمولی و یک معمار نرمافزار حرفهای را مشخص میکند.
با ترکیب ساختارهای داده (مانند کاری که در کش LRU انجام دادیم)، میتوانید سیستمهایی توسعه دهید که در لودهای کاری بسیار سنگین (High-Throughput)، پایداری و سرعت فوقالعادهای از خود نشان دهند.














0 نظر
هنوز نظری برای این مقاله ثبت نشده است.