
پادشاهِ کُدنویسا شو!

بسیاری از توسعهدهندگان بر این باورند که استفاده از مدلهای پیشرفته یادگیری عمیق تنها به اکوسیستم پایتون محدود میشود. اما خوشبختانه، با ابزارها و کتابخانههای قدرتمندی که برای اکوسیستم .NET توسعه داده شده، اکنون میتوان به سادگی این مدلهای پیشرفته را در برنامههای C# نیز به کار گرفت.
در این مقاله، به صورت گام به گام و با زبانی ساده، به بررسی نحوه استفاده از مدل YOLOv8 برای تشخیص اشیاء مختلف در تصاویر با استفاده از پلتفرم .NET خواهیم پرداخت. ما مراحل کلیدی از جمله بارگذاری مدل، پیشپردازش تصاویر، اجرای مدل برای تشخیص و در نهایت، نمایش نتایج را به طور کامل توضیح خواهیم داد.
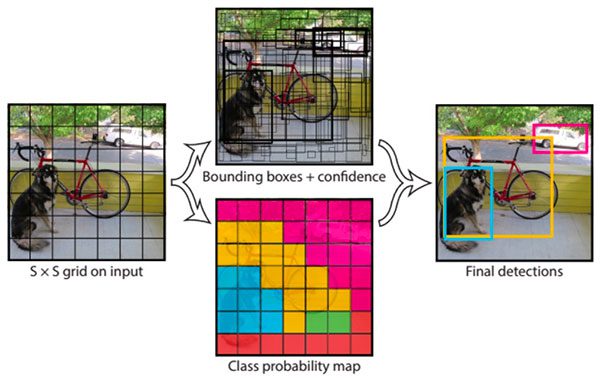
YOLO یک الگوریتم تشخیص شیء مبتنی بر شبکههای عصبی کانولوشنی (CNN) است که انقلابی در زمینه بینایی ماشین ایجاد کرد. نام آن، "You Only Look Once" (شما فقط یک بار نگاه میکنید)، به خوبی فلسفه اصلی آن را توصیف میکند. برخلاف مدلهای قدیمیتر دو مرحلهای (مانند R-CNN) که ابتدا باید مناطق احتمالی حاوی شیء را در تصویر پیدا کرده و سپس هر منطقه را جداگانه طبقهبندی میکردند، YOLO کل فرآیند را در یک مرحله انجام میدهد.
این الگوریتم تصویر را تنها یک بار مشاهده میکند و به طور همزمان موقعیت کادرهای احاطهکننده (Bounding Boxes) و برچسب کلاس هر شیء را پیشبینی میکند. این رویکرد یکپارچه باعث میشود YOLO به طرز چشمگیری سریعتر از رقبای خود باشد و بتواند تشخیص اشیاء را با نرخ فریم بالا (مثلاً در ویدئوها) انجام دهد، در حالی که دقت بالایی را نیز حفظ میکند.
یکی از بزرگترین چالشها در استفاده از مدلهای یادگیری عمیق در پلتفرمهای مختلف، عدم سازگاری بین فریمورکهاست. مدلی که با PyTorch (در پایتون) آموزش داده شده، به طور مستقیم در .NET قابل استفاده نیست. اینجاست که ONNX (Open Neural Network Exchange) وارد میدان میشود.
ONNX یک فرمت استاندارد و متنباز برای نمایش مدلهای یادگیری ماشین است. این فرمت به توسعهدهندگان اجازه میدهد تا مدلها را بین فریمورکهای مختلف (مانند PyTorch, TensorFlow, و ML.NET) جابجا کنند. برای استفاده از YOLO در .NET، ما ابتدا به یک مدل YOLO نیاز داریم که به فرمت .onnx تبدیل (export) شده باشد. خوشبختانه، مدلهای از پیش آموزشدیده YOLO با فرمت ONNX به راحتی در دسترس هستند.
حالا بیایید وارد بخش عملی شویم و یک برنامه کنسول ساده در C# بنویسیم که یک تصویر را به عنوان ورودی دریافت کرده و اشیاء داخل آن را با استفاده از YOLOv8 تشخیص دهد.
گام اول: ایجاد پروژه و نصب پکیجهای لازم
ابتدا، یک پروژه جدید از نوع "Console App" در ویژوال استودیو یا با استفاده از .NET CLI ایجاد کنید.
dotnet new console -n YoloObjectDetection
cd YoloObjectDetection
برای کار با مدل YOLOv8، ما از یک کتابخانه فوقالعاده کارآمد به نام Compunet.YoloV8 استفاده خواهیم کرد. این پکیج NuGet فرآیند بارگذاری مدل، پیشپردازش تصویر و تفسیر نتایج را به شدت ساده میکند. همچنین برای کار با تصاویر و ترسیم نتایج، از کتابخانه محبوب SixLabors.ImageSharp استفاده میکنیم.
این پکیجها را با دستورات زیر نصب کنید:
dotnet add package Compunet.YoloV8
dotnet add package SixLabors.ImageSharp
dotnet add package SixLabors.ImageSharp.Drawing
گام دوم: تهیه مدل YOLOv8 با فرمت ONNX
شما به یک فایل مدل با پسوند .onnx نیاز دارید. میتوانید جدیدترین مدلهای YOLOv8 را که توسط تیم Ultralytics آموزش داده شدهاند، از ریپازیتوری گیتهاب آنها دانلود کنید. این مدلها در اندازههای مختلفی (مانند n برای nano یا l برای large) ارائه میشوند که بین سرعت و دقت تعادل برقرار میکنند. برای شروع، yolov8n.onnx یک انتخاب عالی است.
فایل .onnx دانلود شده را در پوشه پروژه خود قرار دهید و در تنظیمات Properties آن در ویژوال استودیو، گزینه Copy to Output Directory را بر روی Copy if newer تنظیم کنید تا همیشه در کنار فایل اجرایی برنامه کپی شود.
گام سوم: بارگذاری مدل و اجرای تشخیص
اکنون زمان کدنویسی است. فایل Program.cs را باز کرده و کدهای زیر را در آن بنویسید. این کدها مراحل اصلی را پوشش میدهند:
آمادهسازی مسیرها: تعریف مسیر تصویر ورودی، مدل ONNX و تصویر خروجی.
بارگذاری مدل: ایجاد یک نمونه از YoloPredictor با استفاده از فایل مدل.
اجرای تشخیص: فراخوانی متد Detect بر روی تصویر ورودی.
پردازش نتایج: نتایج شامل لیستی از اشیاء شناسایی شده به همراه کادر احاطهکننده، برچسب و میزان اطمینان (Confidence) است.
ترسیم نتایج: استفاده از ImageSharp برای کشیدن کادرها و برچسبها بر روی تصویر اصلی.
ذخیره خروجی: ذخیره تصویر نهایی با اشیاء مشخص شده.
using Compunet.YoloV8;
using SixLabors.ImageSharp;
using SixLabors.ImageSharp.Processing;
using SixLabors.ImageSharp.Drawing.Processing;
using SixLabors.ImageSharp.Drawing;
using SixLabors.Fonts;
// 1. آمادهسازی مسیرها
var imagePath = "path/to/your/image.jpg"; // مسیر تصویر ورودی خود را وارد کنید
var modelPath = "yolov8n.onnx"; // نام فایل مدل ONNX
var outputPath = "output.jpg"; // نام فایل خروجی
Console.WriteLine("در حال بارگذاری مدل...");
// 2. بارگذاری مدل با استفاده از using برای آزادسازی منابع
using var predictor = new YoloPredictor(modelPath);
Console.WriteLine("در حال تشخیص اشیاء در تصویر...");
// 3. اجرای تشخیص روی تصویر
var result = predictor.Detect(imagePath);
// بارگذاری تصویر با ImageSharp برای ترسیم نتایج
using var image = Image.Load(imagePath);
// 4. پردازش و ترسیم نتایج
if (result.Boxes.Count > 0)
{
Console.WriteLine($"تعداد {result.Boxes.Count} شیء شناسایی شد.");
// تعریف فونت برای نمایش برچسبها
var font = SystemFonts.CreateFont("Arial", 16, FontStyle.Bold);
foreach (var box in result.Boxes)
{
// دریافت مختصات، برچسب و میزان اطمینان
var x = box.Rectangle.X;
var y = box.Rectangle.Y;
var width = box.Rectangle.Width;
var height = box.Rectangle.Height;
var label = box.Class.Name;
var confidence = box.Confidence;
var color = box.Class.Color; // کتابخانه به صورت خودکار یک رنگ برای هر کلاس در نظر میگیرد
// 5. ترسیم کادر احاطهکننده و برچسب
image.Mutate(ctx =>
{
// ترسیم مستطیل دور شیء
ctx.DrawRectangles(color, 2, new RectangleF(x, y, width, height));
// ایجاد متن برچسب به همراه درصد اطمینان
var text = $"{label} ({confidence:P2})";
var textSize = TextMeasurer.MeasureSize(text, new TextOptions(font));
// ترسیم پسزمینه برای متن
ctx.Fill(color, new RectangleF(x, y - textSize.Height - 3, textSize.Width, textSize.Height + 5));
// ترسیم متن برچسب
ctx.DrawText(text, font, Color.White, new PointF(x, y - textSize.Height - 3));
});
}
}
else
{
Console.WriteLine("هیچ شیئی در تصویر شناسایی نشد.");
}
// 6. ذخیره تصویر خروجی
image.Save(outputPath);
Console.WriteLine($"تصویر خروجی با موفقیت در مسیر {outputPath} ذخیره شد.");
گام چهارم: اجرا و مشاهده نتایج
قبل از اجرا، مطمئن شوید که یک تصویر مناسب (مثلاً تصویری از یک خیابان با ماشینها و افراد) را در مسیر مشخص شده در متغیر imagePath قرار دادهاید. سپس برنامه را اجرا کنید:
dotnet run
برنامه مدل را بارگذاری کرده، اشیاء را تشخیص داده و یک فایل خروجی به نام output.jpg در پوشه پروژه ایجاد میکند. این تصویر، نسخه اصلی تصویر شماست که بر روی آن، اشیاء شناسایی شده با کادرهای رنگی و برچسبهای مربوطه مشخص شدهاند.
YoloPredictor: این کلاس از کتابخانه Compunet.YoloV8 قلب عملیات ماست. این کلاس به طور خودکار وظایف پیچیدهای مانند تغییر اندازه تصویر به ابعاد مورد نیاز مدل (معمولاً 640x640)، نرمالسازی مقادیر پیکسلها و اجرای جلسه استنتاج (inference session) با ONNX Runtime را انجام میدهد.
DetectionResult: خروجی متد Detect یک شیء از این نوع است که شامل لیستی از Box ها میباشد. هر Box حاوی اطلاعات کاملی در مورد یک شیء شناسایی شده است:
Rectangle: مختصات کادر احاطهکننده (X, Y, Width, Height).
Class: شامل نام کلاس (Name) و یک رنگ پیشنهادی (Color).
Confidence: یک عدد بین 0 و 1 که نشاندهنده میزان اطمینان مدل از صحت این تشخیص است.
فیلتر کردن نتایج: مدل YOLO معمولاً تعداد زیادی تشخیص با اطمینان پایین تولید میکند. کتابخانه Compunet.YoloV8 به طور پیشفرض این تشخیصهای ضعیف را فیلتر میکند. شما میتوانید این آستانهها (thresholds) را برای دقت بیشتر سفارشیسازی کنید.
پردازش با GPU: برای افزایش چشمگیر سرعت تشخیص (مخصوصاً برای ویدئوها)، میتوانید از قدرت پردازنده گرافیکی (GPU) استفاده کنید. برای این کار کافیست به جای پکیج Compunet.YoloV8، نسخه مخصوص GPU آن یعنی Compunet.YoloV8.Gpu را نصب کنید و مطمئن شوید که درایورهای CUDA انویدیا بر روی سیستم شما نصب است. کتابخانه به طور خودکار از GPU استفاده خواهد کرد.
همانطور که مشاهده کردید، ادغام مدلهای پیشرفته هوش مصنوعی مانند YOLO در اکوسیستم .NET نه تنها ممکن، بلکه به لطف ابزارهایی مانند ONNX Runtime و کتابخانههای سطح بالا، بسیار ساده و کارآمد است. توسعهدهندگان .NET دیگر نیازی به مهاجرت به پلتفرمهای دیگر برای بهرهمندی از آخرین دستاوردهای یادگیری عمیق ندارند.
این مقاله تنها نقطه شروعی برای کاوش در دنیای وسیع بینایی ماشین در .NET است. شما میتوانید این پروژه را گسترش داده و از آن برای پردازش فریمهای ویدئویی از وبکم، تحلیل تصاویر در یک سرویس وب (Web API)، یا ایجاد برنامههای دسکتاپ هوشمند استفاده کنید. قدرت YOLO و سادگی .NET ترکیبی برنده برای ساخت نسل بعدی برنامههای هوشمند است.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.