
پادشاهِ کُدنویسا شو!
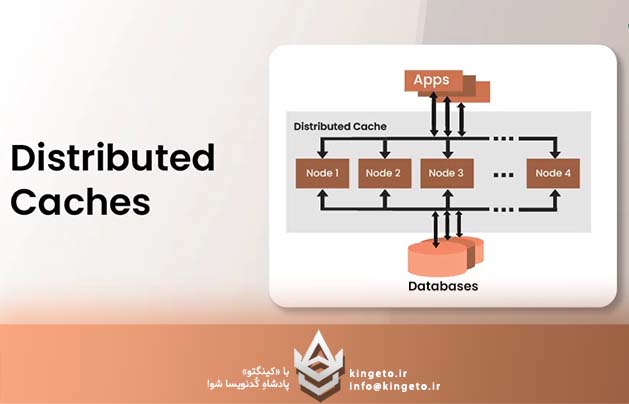
کش توزیعشده سیستمی است که دادهها را در حافظه موقت (In-memory) چندین سرور که به صورت یک شبکه واحد عمل میکنند، ذخیره میکند. برخلاف کشینگ محلی (Local Caching) که دادهها را در حافظه همان سرورِ اپلیکیشن نگه میدارد، کش توزیعشده اجازه میدهد تمامی گرههای (Nodes) یک سیستم به یک منبع داده مشترک و پرسرعت دسترسی داشته باشند.
چرا به کش توزیعشده نیاز داریم؟
کاهش فشار روی دیتابیس: جلوگیری از اجرای کوئریهای تکراری و سنگین.
دسترسی با تأخیر در حد میلیثانیه: سرعت RAM هزاران برابر بیشتر از SSD یا HDD است.
پایداری (High Availability): در صورت خرابی یک گره، دادهها در گرههای دیگر در دسترس هستند.
مقیاسپذیری افقی: با افزایش ترافیک، میتوان سرورهای جدیدی به خوشه (Cluster) کش اضافه کرد.
انتخاب استراتژی مناسب بستگی به نوع داده و اولویت میان «سرعت» و «سازگاری داده» (Data Consistency) دارد.
الف) Cache-Aside (Lazy Loading)
این رایجترین استراتژی است. اپلیکیشن ابتدا کش را چک میکند:
اگر داده موجود بود (Cache Hit): مستقیماً بازگردانده میشود.
اگر موجود نبود (Cache Miss): داده از دیتابیس خوانده شده، در کش ذخیره شده و سپس به کاربر داده میشود.
مزیت: انعطافپذیری بالا و مدیریت دستی دادهها.
ب) Read-Through
در این مدل، اپلیکیشن فقط با کش در ارتباط است. اگر داده در کش نباشد، خودِ سیستمِ کش مسئول خواندن داده از دیتابیس و بهروزرسانی خودش است.
مزیت: سادهسازی کد سمت اپلیکیشن.
ج) Write-Through
هرگاه دادهای آپدیت شود، همزمان هم در کش و هم در دیتابیس نوشته میشود.
مزیت: تضمین میکند که دادههای کش همیشه با دیتابیس همگام هستند.
عیب: افزایش تأخیر در زمان نوشتن.
د) Write-Behind (Write-Back)
داده ابتدا در کش نوشته شده و پس از یک فاصله زمانی (به صورت نامتقارن/Asynchronous)، در دیتابیس ذخیره میشود.
مزیت: سرعت نوشتن فوقالعاده بالا.
هشدار: خطر از دست رفتن داده در صورت کرش کردن سرور کش قبل از ذخیره در دیتابیس.
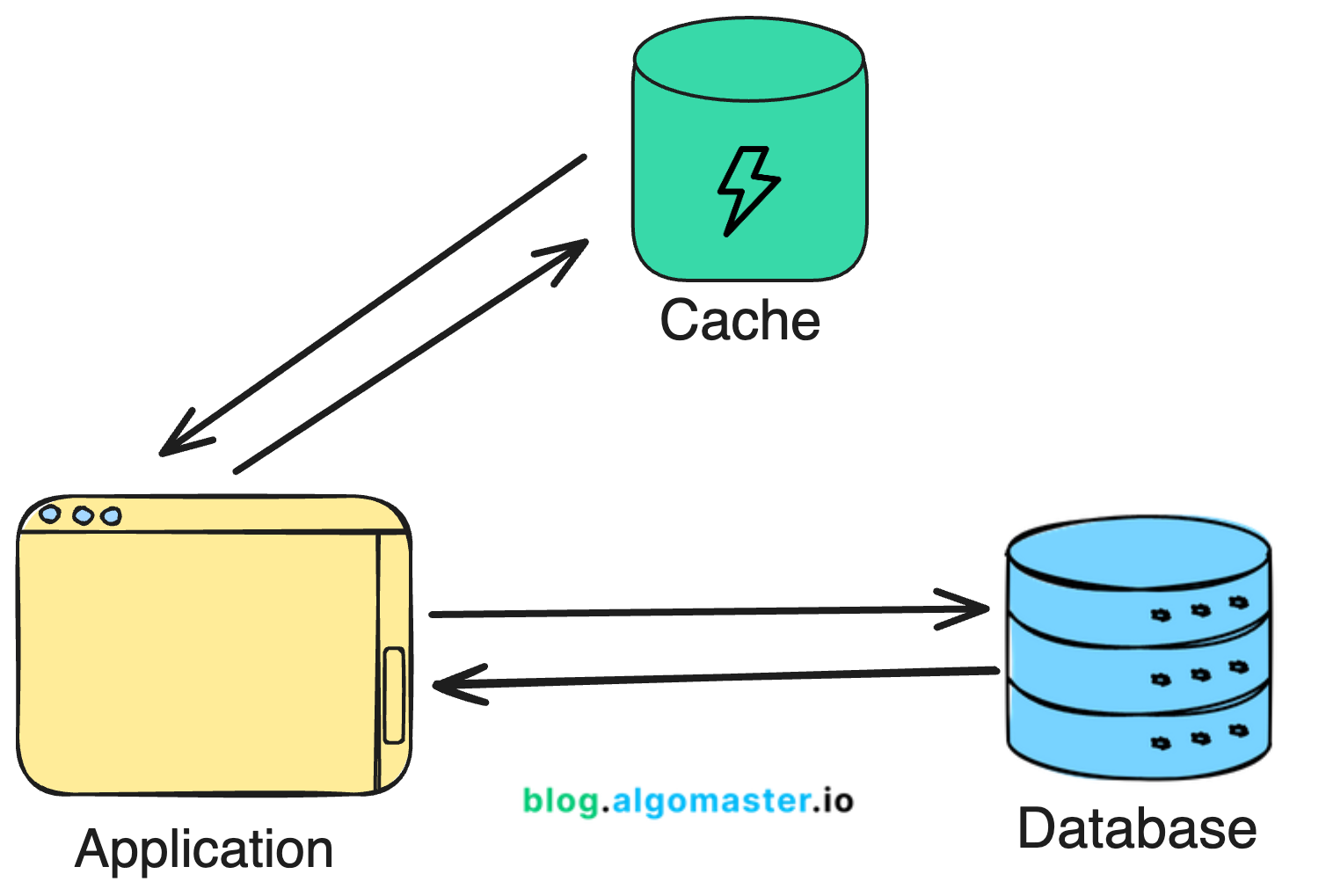
حافظه رم محدود است؛ بنابراین سیستم کش باید بداند چه زمانی دادههای قدیمی را پاک کند.
LRU (Least Recently Used): دادههایی که در طولانیترین زمان اخیر استفاده نشدهاند، حذف میشوند. این محبوبترین روش است.
LFU (Least Frequently Used): دادههایی که کمترین تعداد دفعات استفاده را داشتهاند حذف میشوند.
FIFO (First In, First Out): قدیمیترین داده وارد شده، اولین دادهای است که خارج میشود.
TTL (Time To Live): تعیین یک زمان انقضا (مثلاً ۶۰ دقیقه) برای هر آیتم در کش.
در یک سیستم توزیعشده با چندین گره، چگونه بفهمیم هر کلید (Key) در کدام سرور ذخیره شده است؟ استفاده از روش ساده Hash(key) % N (که N تعداد سرورهاست) مشکل بزرگی دارد: اگر یک سرور کم یا زیاد شود، جایگاه اکثر کلیدها تغییر میکند و باعث Cache Miss عظیم میشود.
Consistent Hashing این مشکل را حل میکند. در این روش، سرورها و کلیدها روی یک دایره فرضی قرار میگیرند و هر کلید به نزدیکترین سرور در جهت عقربههای ساعت اختصاص مییابد. با حذف یا اضافه شدن یک سرور، فقط بخش کوچکی از کلیدها نیاز به جابهجایی دارند.
الف) Cache Stampede (هجوم ناگهانی)
زمانی رخ میدهد که یک کلید پرکاربرد منقضی میشود و ناگهان هزاران درخواست همزمان به سمت دیتابیس سرازیر میشوند تا آن کلید را بازسازی کنند.
راه حل: استفاده از قفلهای توزیعشده (Distributed Locking) یا تمدید زمان انقضا قبل از اتمام واقعی.
ب) Hot Keys
برخی دادهها (مثلاً پروفایل یک سلبریتی) بسیار بیشتر از سایرین فراخوانی میشوند. این باعث فشار بیش از حد به یک گره خاص در خوشه میشود.
راه حل: ایجاد کپیهای محلی (Local Replication) از آن کلید در تمامی گرهها.
ج) چالش Consistency (همگامی داده)
در سیستمهای توزیعشده، همیشه تضادی بین در دسترس بودن (Availability) و سازگاری (Consistency) وجود دارد (قضیه CAP). گاهی ممکن است اپلیکیشن دادهای قدیمی را از کش بخواند در حالی که دیتابیس آپدیت شده است.
۱. Redis (Remote Dictionary Server)
محبوبترین ابزار کشینگ در جهان.
ویژگیها: پشتیبانی از ساختارهای داده پیچیده (Lists, Sets, Hashes)، قابلیت Persistence (ذخیره روی دیسک) و مدل Pub/Sub.
مناسب برای: سیستمهای Real-time، صفهای پیام و کشینگ عمومی.
۲. Memcached
سادهتر و سریعتر برای کارهای ابتدایی.
ویژگیها: معماری Multi-threaded که در سیستمهای بسیار بزرگ با کوئریهای ساده عملکرد بهتری از ردیس تکرشتهای (در نسخههای قدیمی) داشت.
مناسب برای: کشینگ ساده کلید-مقدار.
۳. NCache
یک کش توزیعشده بومی برای اکوسیستم .NET.
ویژگیها: یکپارچگی کامل با SQL Server و قابلیتهایی مانند SQL Dependency (پاک شدن خودکار کش در صورت تغییر در جدول دیتابیس).
برای مدیریت یک کش موفق، باید این شاخصها را زیر نظر بگیرید:
Cache Hit Ratio: درصد درخواستهایی که در کش پاسخ داده شدهاند. (ایدهآل بالای ۸۰-۹۰٪).
Memory Usage: چقدر از ظرفیت رم اشغال شده است.
Eviction Rate: سرعت حذف دادهها توسط الگوریتم LRU. اگر این عدد بالا باشد، یعنی حافظه اختصاص یافته کم است.
Latency: زمان پاسخگویی گرههای کش.
کشیینگ توزیعشده دیگر یک "انتخاب" نیست، بلکه برای اپلیکیشنهای مقیاسپذیر یک "ضرورت" است. با انتخاب درست استراتژی (مانند Cache-Aside)، الگوریتم انقضا (مانند LRU) و ابزار مناسب (مانند Redis یا NCache)، میتوان بار دیتابیس را به شدت کاهش داد و تجربهای روان و سریع برای کاربران فراهم کرد. با این حال، همیشه باید به خاطر داشت که مدیریت کش، پیچیدگیهای خاص خود را در زمینه همگامی دادهها دارد و باید با دقت طراحی شود.

















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.